|
Программные системы и вычислительные методы
Оформленная ссылка на статью:
Капитонова М.С., Андреев А.А., Попов Д.И. Применение методов машинного обучения для выявления мошеннических транзакций в банковских системах // Программные системы и вычислительные методы. 2026. № 2. С. 202-216. DOI: 10.7256/2454-0714.2026.2.79787 EDN: IFKUIQ URL: https://nbpublish.com/library_read_article.php?id=79787
Применение методов машинного обучения для выявления мошеннических транзакций в банковских системах
Капитонова Мария Сергеевна
магистрант; Кафедра информационных технологий и математики; Сочинский государственный университет
354008, Россия, Краснодарский край, г. Сочи, ул. Политехническая, д. 7
Kapitonova Mariia Sergeevna
Graduate student; Department of Information Technology and Mathematics; Sochi State University
7 Politechnicheskaya str., Sochi, Krasnodar Territory, 354008, Russia

|
kapitonova_imarya@mail.ru
|
|
 |
Андреев Андрей Андреевич
магистрант; МАТИ - Российский государственный технологический университет им. К.Э. Циолковского; Московский авиационный институт (национальный исследовательский университет)
125080, Россия, г. Москва, р-н Сокол, Волоколамское шоссе, д. 4
Andreev Andrei Andreevich
Graduate student; MATI - Russian State Technological University named after K.E. Tsiolkovsky; Moscow Aviation Institute (National Research University)
Sokolov district, Volokolamsk highway, 4, Moscow, 125080, Russia
|
|
aaandreyev@mail.ru
|
|
 |
|
Попов Дмитрий Иванович
доктор технических наук
профессор; Кафедра информационных технологий и математики; Сочинский государственный университет
354008, Россия, Краснодарский край, г. Сочи, ул. Политехническая, д. 7
Popov Dmitrii Ivanovich
Doctor of Technical Science
Professor; Department of Information Technology and Mathematics; Sochi State University
7 Politechnicheskaya str., Sochi, Krasnodar Territory, 354008, Russia
|
|
damitry@mail.ru
|
|
 |
|
DOI: 10.7256/2454-0714.2026.2.79787
EDN:
IFKUIQ
Дата направления статьи в редакцию:
07-05-2026
Дата получения первой рецензии с формулировкой «Отправлена на доработку с рекомендациями рецензента»: 12-05-2026 21:20
Дата
доработки рукописи автором после первой рецензии:
20-05-2026 07:21
Дата получения последней положительной рецензии с рекомендацией «опубликовать»: 22-05-2026 06:55
Статья публикуется в одобренном рецензентами варианте (после получения последней положительной рецензии, рекомендующей рукопись к публикации) с исправлениями автора (внесенными им после получения предварительных рецензий, рекомендующих рукопись к доработке).
Все рецензии (включая предварительные рецензии) опубликованы в открытом доступе непосредственно за текстом самой статьи. Все варианты авторских исправлений хранятся в депозитарии издательства и могут быть доступны по требованию уполномоченных организаций.
Прочитать все рецензии на эту статью
Дата публикации:
24-05-2026
Аннотация:
Статья посвящена исследованию методов машинного обучения для выявления мошеннических транзакций в банковских системах. Актуальность обусловлена ростом объема финансовых операций, усложнением схем мошенничества и ограниченной эффективностью традиционных методов контроля, основанных на фиксированных правилах. В условиях выраженной несбалансированности данных задача обнаружения мошенничества требует применения адаптивных подходов к классификации. Целью исследования является анализ возможностей применения методов машинного обучения для повышения качества выявления подозрительных транзакций. Предметом исследования является выбор и настройка моделей Random Forest и XGBoost для бинарной классификации банковских транзакций на конкретном датасете, а также оценка влияния порогового значения классификации на качество обнаружения мошенничества. Рассматриваются обезличенные транзакции клиентов коммерческого банка. Исследовательский вопрос заключается в том, позволяет ли целенаправленная настройка порога для конкретного набора банковских операций добиться приемлемого баланса между полнотой выявления мошенничества и числом ложноположительных срабатываний по сравнению с использованием стандартного порога 0.5. Использованы методы предварительной обработки данных, включая преобразование признаков, кодирование категориальных переменных и корреляционный анализ. Для решения задачи классификации применялись алгоритмы Random Forest и XGBoost с последующей настройкой параметров и анализом влияния порогового значения классификации на целевые метрики. Научная новизна работы заключается в детальном исследовании влияния выбора порогового значения классификации на качество выявления мошеннических транзакций на реальном сильно несбалансированном датасете. Подход основан на анализе зависимостей метрик precision, recall и F1-score от порога и выборе значения, обеспечивающего компромисс между полнотой выявления мошенничества и допустимым уровнем ложноположительных срабатываний с учетом специфики антифрод‑систем. Установлено, что алгоритм XGBoost демонстрирует более устойчивые результаты по сравнению с Random Forest за счет лучшего учета нелинейных зависимостей и чувствительности к редкому классу. Показано, что настройка порога классификации позволяет повысить полноту обнаружения мошенничества при контролируемом уровне ложноположительных срабатываний. Практическая значимость исследования заключается в возможности применения предложенного подхода для мониторинга банковских операций, повышения эффективности выявления подозрительных транзакций и поддержки принятия решений в системах противодействия мошенничеству.
Ключевые слова:
искусственный интеллект, машинное обучение, методы машинного обучения, анализ данных, банк, банковские системы, банковские транзакции, выявление мошенничества, антифрод, финансовые учреждения
Abstract: The article is dedicated to the study of machine learning methods for detecting fraudulent transactions in banking systems. The relevance of the work is determined by the increase in the volume of financial operations, the complexity of fraud schemes, and the limited effectiveness of traditional control methods based on fixed rules. Given the pronounced data imbalance, the task of detecting fraudulent activities requires the application of adaptive classification approaches. The aim of the research is to analyze the potential of machine learning methods to enhance the quality of identifying suspicious transactions. The study employed data preprocessing methods, including feature transformation, categorical variable encoding, and correlation analysis, as well as a comparative analysis of random forest and gradient boosting algorithms. The research investigated the impact of the classification threshold on the quality of fraud detection. It was established that the gradient boosting method demonstrates more stable results compared to the random forest method due to better consideration of nonlinear dependencies and sensitivity to the rare class. It was shown that adjusting the classification threshold allows for increased recall in fraud detection while maintaining controlled levels of false positives. The practical significance of the work lies in the potential application of the proposed approach for monitoring banking operations and supporting decision-making in anti-fraud control systems. The study utilized data preprocessing and analysis methods, including feature transformation, categorical variable encoding, and correlation analysis. For the classification task, Random Forest and XGBoost algorithms were employed, followed by an analysis of the classification threshold. The scientific novelty of the work lies in investigating the impact of the classification threshold on the quality of detecting fraudulent transactions under conditions of imbalanced data. It was established that using the gradient boosting algorithm (XGBoost) enhances the model's robustness to the rare class compared to the random forest method (Random Forest) due to more effective consideration of nonlinear dependencies among features. It was shown that changing the classification threshold allows for regulating the balance between recall in fraud detection and the number of false positives, depending on the practical requirements of the anti-fraud system. The practical significance of the research lies in the applicability of the proposed approach for monitoring banking operations, improving the efficiency of identifying suspicious transactions, and supporting decision-making in fraud prevention systems.
Keywords:
artificial intelligence, machine learning, machine learning methods, data analysis, bank, banking systems, banking transactions, fraud detection, anti-fraud, financial institutions
Введение
В настоящее время обеспечение безопасности транзакций и защита активов клиентов являются актуальными и приоритетными задачами для любой финансовой организации. Ущерб от финансового мошенничества в мире за последние годы продолжает расти. Например, в первом квартале 2025 года суммарный ущерб клиентов банка от действий мошенников составил 6,9 миллиарда рублей [5]. Параллельно с развитием технологий усложняются и масштабируются мошеннические сценарии, что создает риск значительных финансовых потерь и подрыва доверия клиентов к банкам. Традиционные методы мониторинга, основанные на фиксированных правилах, перестают быть эффективными, так как не обладают достаточной гибкостью для адаптации к новым угрозам. В связи с этим банкам необходимо совершенствовать инструменты обнаружения и предотвращения подозрительных транзакций. Для решения данной проблемы требуется разработка стратегии, способствующей повышению точности выявления мошеннической активности.
Отмывание денежных средств является существенной угрозой для финансовых систем, поскольку оказывает негативное влияние на устойчивость банковского сектора. Данный процесс заключается в легализации доходов, полученных незаконным путем.
Современное развитие банковского сектора сопровождается ростом объема операций и усложнением цифровых сервисов, что приводит к увеличению рисков мошеннической активности. При этом, следует отметить, что с течением времени схемы мошеннических транзакций эволюционируют и усложняются, включая в себя новые уровни, что, в свою очередь, создает трудности в их выявлении. Данное обстоятельство обуславливает невозможность выявления подобных схем традиционными методами, основанными на фиксированных правилах и данных, недостатками которых выступают ограниченная гибкость, низкая эффективность при работе с большими объемами данных и слабая адаптация к новым мошенническим схемам. Нивелирование описанных недостатков возможно посредством использования технологий машинного обучения, обладающих возможностями работы и анализа больших массивов данных в целях выявления скрытых зависимостей и обнаружения подозрительных операций на основе динамичного и адаптивного подхода [2].
Целью настоящего исследования выступает построение предсказательной модели, а также анализ ее вероятностных выходов, позволяющий регулировать баланс между полнотой обнаружения мошенничества и числом ложных срабатываний [9].
В данной работе рассматривается подход к выявлению мошеннических транзакций на основе применения методов машинного обучения и подбора порогового значения классификации. Исследуется влияние изменения порога на качество обнаружения мошеннических операций в условиях несбалансированных данных.
Научная новизна работы состоит в разработке и апробации подхода к выбору порогового значения классификации в задаче выявления мошеннических транзакций в условиях несбалансированных данных. Предлагаемый подход основан на анализе зависимостей метрик precision, recall и F1-score от порога и выборе такого порогового значения, которое обеспечивает компромисс между полнотой выявления мошенничества и допустимым уровнем ложноположительных срабатываний с учетом специфики антифрод‑систем. Показано, что применение алгоритма XGBoost в сочетании с данным подходом позволяет повысить устойчивость модели к редкому классу по сравнению с Random Forest. Практическая значимость исследования заключается в возможности применения предложенного подхода для мониторинга банковских операций, повышения эффективности выявления подозрительных транзакций и поддержки принятия решений в системах противодействия мошенничеству.
Материалы и методы
В работе рассматривается задача выявления мошеннических транзакций на основе анализа данных банковских операций. Исследование выполнено на основе обезличенного набора данных о транзакциях клиентов коммерческого банка, содержащего сведения об операциях, счетах и клиентах. Это позволяет исследовать поведенческие паттерны клиентов и выявлять отклонения от типичного финансового поведения, которые могут свидетельствовать о мошеннической активности.
Набор данных включает 200000 наблюдений и 24 признака, описывающих параметры транзакций и базовые характеристики клиентов. Признаки представлены числовыми и категориальными типами. Целевая переменная является бинарной и отражает факт отнесения транзакции к мошенническим.
При анализе данных использовался язык программирования Python с такими библиотеками, как Pandas для работы с данными, Matplotlib для визуализации и Scikit-learn для решения задач машинного обучения и статистического анализа [11].
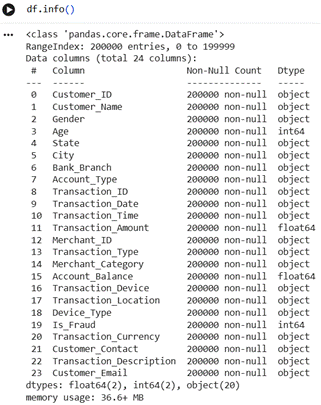
Рисунок 1 – Сводная информация о наборе данных
Источник: составлено автором
Был произведен анализ данных, используемых для выявления мошеннических транзакций, который показал, что для успешного решения поставленной задачи, используемые данные должны быть подготовлены в несколько этапов [4].
На этапе предварительной обработки данных была выполнена проверка качества датасета. Пропущенные значения и дублирующиеся записи отсутствовали. Из рассматриваемого набора данных были исключены идентификаторы клиентов и транзакций, а также категориальные признаки, не являющиеся информативными для задачи выявления мошенничества (служебные идентификаторы, текстовые описания без вариативности), в целях повышения информативности модели. Также были удалены признаки, которые содержат одно уникальное значение, для уменьшения размерности и минимизации воздействия нерелевантных данных на процессы обучения моделей.
Анализ распределения классов позволил выявить выраженную несбалансированность, согласно которой около 5% от совокупного объема транзакций относятся к мошенническим операциям. Подобная выраженная несбалансированность характерна для задач антифрода и существенно усложняет обучение модели за счет того, что обычные показатели качества в описанных условиях не позволяют оценить возможности алгоритма по обнаружению редких и наиболее значимых транзакций.
Для нивелирования описанных выше рисков и сложности при проведении оценки результатов внимание акцентировалось на чувствительных к распознаванию редкого класса метриках.
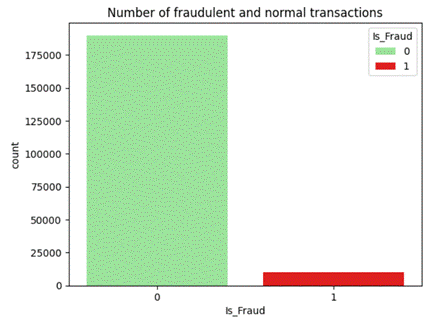
Рисунок 2 – Распределение целевых классов
Источник: составлено автором
По результатам детального анализа категориальных признаков на основе диаграмм был сделан вывод об отсутствии выраженных различий между классами, что подтверждает сложность задачи и обусловливает необходимость использования методов машинного обучения для выявления скрытых зависимостей в данных. Также по результатам анализа было принято решение о необходимости преобразования временных признаков, в частности, дата и время транзакции делились на ряд составных компонентов – дни, минуты, часы, секунды в целях учета временных закономерностей поведения клиентов.
Преобразование категориальных признаков в числовой формат посредством использования комбинированного подхода позволило сохранить информативность переменных при одновременном снижении их размерности. В частности, для признаков с небольшим числом уникальных значений использовался One-Hot Encoding, а для признаков с большим числом – Target Encoding.
В рамках выполнения задачи настоящего исследования также была проведена оценка корреляционных зависимостей между числовыми признаками с целью исключения признаков с выявленной высокой взаимной корреляцией для уменьшения избыточности и нивелирования риска переобучения модели [7]. Данная операция позволила сформировать очищенную и преобразованную совокупность признаков, наилучшим образом подходящую для построения классификационных моделей.
Задача по выявлению мошеннических транзакций была сформулирована как задача бинарной классификации, в рамках которой для каждой транзакции проводилась оценка вероятности принадлежности к классу мошенничества с использованием формулы (1).
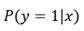 , (1) , (1)
где
x – вектор признаков транзакции,
y – целевая переменная.
В целях поддержания баланса между полнотой выявления мошеннических транзакций и уровнем ложных срабатываний решение о принадлежности объекта к тому или иному классу принималось на основе пороговых значений вероятности.
Для решения задачи были выбраны следующие методы машинного обучения: ансамблевые алгоритмы Random Forest и градиентный бустинг XGBoost. Оба метода хорошо подходят для работы с табличными данными и позволяют учитывать нелинейные зависимости между признаками.
Разделение исходного набора данных осуществлялось на обучающую и тестовую выборки в соотношении 80/20. При формировании выборок применялась стратификация по целевой переменной, что обеспечивало сохранение исходного соотношения классов в обучающей и тестовой частях.
Для учета дисбаланса классов применялись встроенные механизмы взвешивания, а также методы балансировки данных [6]. Для модели Random Forest применялось взвешивание классов (class_weight='balanced'). Такой подход позволил повысить чувствительность моделей к выявлению мошеннических транзакций.
Для модели Random Forest были заданы следующие основные гиперпараметры: число деревьев n_estimators = 300, фиксированное значение random_state = 42, а также параллельная обработка вычислений (n_jobs = -1).
Для модели XGBoost использовались параметры n_estimators = 600, max_depth = 4, learning_rate = 0.05, subsample = 0.8. Параметр scale_pos_weight рассчитывался на основе соотношения классов обучающей выборки, что позволяло дополнительно учитывать дисбаланс при оптимизации модели.
Настройка гиперпараметров выполнялась методом ручного подбора на основе серии экспериментов на обучающей выборке.
Оценка качества моделей проводилась на тестовой выборке с использованием метрик precision, recall, F1-score, ROC-AUC и PR-AUC, при особом внимании к метрике recall, так как пропуск мошеннической транзакции в банковских системах имеет более высокую стоимость по сравнению с ложным срабатыванием. Дополнительно анализировалось влияние порога классификации на итоговые показатели качества, что позволяло выбирать режим работы модели с учетом приоритета полноты выявления мошеннических операций.
Для дополнительной оценки качества классификации применялась метрика F1-score (2), позволяющая одновременно учитывать точность и полноту данных.
 (2) (2)
Метрика F1-score особенно эффективна в ситуациях, когда оптимизация одной метрики может повлечь за собой ухудшение другой.
Результаты
По результатам проведенного эксперимента установлено, что модель Random Forest позволяет получить относительно высокое значение общей точности, однако при этом показатели recall и F1-score для мошеннического класса остаются низкими, что свидетельствует об ограниченной эффективности модели при работе с несбалансированными данными. В отличие от нее, модель XGBoost обеспечивает более высокие значения метрик, характеризующих качество выявления мошеннических операций.
В таблице 1 представлены значения основных метрик качества для моделей Random Forest и XGBoost для мошеннического класса при стандартном пороговом значении 0.5 и при подобранных порогах, ориентированных на повышение полноты выявления мошеннических транзакций. Как видно из таблицы 1, при использовании настроенного порога модель XGBoost демонстрирует более высокие значения recall и F1-score для мошеннического класса по сравнению с Random Forest, что указывает на ее лучшую способность обнаруживать редкий класс.
Таблица 1 – Значения метрик качества для моделей Random Forest и XGBoost при разных порогах
|
Модель
|
Порог
|
Precision
|
Recall
|
F1-score
|
|
Random Forest
|
0.5
|
0.10
|
0.05
|
0.07
|
|
Random Forest
|
0.3
|
0.07
|
0.15
|
0.09
|
|
XGBoost
|
0.5
|
0.18
|
0.30
|
0.22
|
|
XGBoost
|
0.454
|
0.12
|
0.65
|
0.20
|
Пороговое значение 0.454 для модели XGBoost было выбрано по максимуму F1-score для мошеннического класса при анализе зависимости метрик от порога.
Влияние порогового значения на показатели качества классификации проявляется в изменении значений метрик precision, recall и F1-score для модели XGBoost. При стандартном пороге 0.5 модель демонстрировала более консервативное поведение и относила к классу мошенничества меньшее число транзакций, в результате чего значение recall оставалось относительно низким, а precision – более высоким. При снижении порога увеличивалось количество операций, отнесенных к положительному классу, что приводило к росту recall и одновременному снижению precision.
Для обеих моделей было установлено, что уменьшение порога приводит к увеличению полноты обнаружения мошеннических транзакций, однако динамика изменения precision и F1-score различается. Наиболее высокие значения метрик, характеризующих качество выявления редкого класса, были получены для XGBoost при использовании подобранного порогового значения. Это позволяет сделать вывод о том, что эффективность модели определяется не только выбором алгоритма, но и точной настройкой пороговых параметров, которая критически важна для достижения оптимального баланса между количеством выявленных мошеннических транзакций и числом ложноположительных срабатываний.
Результаты по обеим моделям показали, что показатели качества изменяются в зависимости от выбранного порога принятия решения.
Обсуждение
Обнаружение мошенничества является сложной задачей, и, несмотря на разработку множества методов для ее решения, обширное экспериментальное сравнение этих методов в литературе по-прежнему ограничено [8]. Полученные в данной работе результаты дополняют существующие исследования, подтверждая, что выраженная несбалансированность классов и слабая разделимость объектов существенно осложняют обучение моделей и интерпретацию показателей качества.
Было показано, что основным фактором, влияющим на качество классификации, является значительное преобладание легитимных операций. Смещение в сторону доминирующего класса приводит к тому, что модель может демонстрировать высокие значения агрегированных метрик (например, точности), при этом обладая низкой способностью выявлять редкий мошеннический класс. Это согласуется с результатами работ, в которых подчеркивается ограниченность традиционных метрик при оценке моделей в условиях дисбаланса классов.
Отмеченные ограничения по значениям recall и F1-score для мошеннического класса сопоставимы с результатами, полученными в зарубежных исследованиях по обнаружению финансового мошенничества, где при сильной несбалансированности данных даже современные модели демонстрируют умеренные значения полноты и F1-score при приемлемой общей точности. При этом преимущество градиентного бустинга над ансамблями на решающих деревьях по метрикам, чувствительным к редкому классу, также отмечается в ряде работ, сравнивающих алгоритмы классического и глубокого машинного обучения для задач fraud detection.
Дополнительной сложностью является слабая разделимость мошеннических и легитимных транзакций: по ряду признаков мошеннические операции оказываются близки к нормальным. В таких условиях более простые модели или модели с недостаточно гибкой структурой склонны формировать границы, ориентированные на основной класс, что приводит к пропуску значительной части мошеннических операций. Это объясняет ограниченные возможности Random Forest при работе на рассматриваемом датасете, несмотря на использование взвешивания классов и методов балансировки данных.
Проведенное в рамках настоящей работы исследование позволило отметить ограниченную способность к обнаружению мошеннических транзакций у Random Forest, что особенно проявляется при работе с несбалансированными данными. Подобные особенности модели нашли отражение в низких значениях recall и F1-score, что обуславливает необходимость дополнительной оптимизации Random Forest или его использование в комбинации с другими методами.
Модель XGBoost продемонстрировала более устойчивые результаты по метрикам, связанным с выявлением мошеннического класса, что можно связать с особенностями алгоритма: использованием градиентного бустинга над деревьями решений, механизмами регуляризации и подвыборки объектов и признаков, а также возможностью явно учитывать дисбаланс через параметр scale_pos_weight. В совокупности это позволяет сгладить влияние шумовых наблюдений и лучше адаптироваться к редкому классу по сравнению с классическим случайным лесом, где контроль над вкладом миноритарного класса реализуется преимущественно через веса классов. В сочетании с подбором порогового значения это позволяет адаптировать модель под практические требования к соотношению между полнотой обнаружения мошенничества и числом ложноположительных срабатываний.
Таким образом, проведенное исследование показывает, что эффективность антифрод-системы определяется не только выбором алгоритма, но и качеством признакового пространства, способом учета дисбаланса и стратегией настройки пороговых значений. Для практического применения это означает необходимость ориентироваться на метрики, чувствительные к редкому классу, и использовать настройку порога в качестве инструмента согласования требований по уровню риска и допустимой нагрузке на службы комплаенса.
Заключение
Финансовое мошенничество представляет собой серьезную угрозу для экономической безопасности, и традиционные методы его обнаружения уже не справляются с растущим объемом и сложностью мошеннических схем [1]. В эпоху больших данных традиционные методы больше не эффективны [10]. В работе рассмотрена задача выявления мошеннических транзакций на основе методов машинного обучения. Проведен анализ исходных данных, выполнена их предобработка, преобразование признаков и построение классификационных моделей. Анализ полученных данных свидетельствует о высокой степени сложности решаемой задачи. Это обусловлено сильной несбалансированностью классов и слабой разделимостью объектов по большинству признаков.
В ходе исследования было установлено, что модель Random Forest имеет ограниченную эффективность при выявлении мошеннических операций. Напротив, XGBoost показал более стабильные результаты по метрикам, связанным с обнаружением мошеннического класса. Кроме того, было выявлено что изменение порогового значения оказывает существенное влияние на соотношение между полнотой выявления мошенничества и числом ложных срабатываний.
Например, при снижении порога для модели XGBoost до настроенного значения удается повысить полноту обнаружения мошеннических транзакций по сравнению со стандартным порогом 0.5 при сохранении контролируемого уровня ложноположительных срабатываний, что делает эту настройку практически значимой для банковского мониторинга.
Практическая значимость работы заключается в возможности применения предложенного подхода для мониторинга транзакций в системах противодействия отмыванию денежных средств. Следует учитывать, что выводы сделаны на основе одного реального датасета с выраженным дисбалансом классов. Проверка устойчивости результатов на других выборках и временных срезах представляется направлением для дальнейших исследований. Результаты исследования согласуются с недавними публикациями по финансовому мошенничеству, в которых обосновывается переход от статичных правил к моделям машинного обучения и демонстрируется рост эффективности выявления подозрительных операций.
Полученные результаты подтверждают целесообразность использования методов машинного обучения совместно с настройкой пороговых значений для повышения эффективности выявления мошеннических транзакций в условиях несбалансированных данных. Недостаточно реагировать на случаи мошенничества по мере их возникновения, необходимо принимать упреждающие меры для укрепления защиты, снижения рисков и защиты возможностей [3].
Статья публикуется в одобренном рецензентами варианте (после получения последней положительной рецензии, рекомендующей рукопись к публикации) с исправлениями автора (внесенными им после получения предварительных рецензий, рекомендующих рукопись к доработке).
Все рецензии (включая предварительные рецензии) опубликованы в открытом доступе непосредственно за текстом самой статьи. Все варианты авторских исправлений хранятся в депозитарии издательства и могут быть доступны по требованию уполномоченных организаций.
Прочитать все рецензии на эту статью
Библиография
1. Алдохина Д.В. Применение методов искусственного интеллекта и машинного обучения для выявления случаев финансового мошенничества // Cifra. Компьютерные науки и информатика. 2025. № 2(6). С. 1-4. DOI: 10.60797/COMP.2025.6.1 EDN: RTKUGP.
2. Аркадьева О.Г., Петров А.В. Модели машинного обучения как инструмент обнаружения подозрительных банковских транзакций // Вестник Сургутского государственного университета. 2025. № 13(3). С. 8-21. DOI: 10.35266/2949-3455-2025-3-1 EDN: WJGCSO.
3. Ермоловская О.Ю. Предотвращение мошеннических транзакций в финансовой сфере // Экономическая безопасность. 2025. Т. 8. № 4. С. 923-942. DOI: 10.18334/ecsec.8.4.123240 EDN: KJHCAW.
4. Осипова Т.А., Зайцев К.С., Биферт В.О. Применение алгоритмов машинного обучения к задаче выявления мошенничества при использовании пластиковых карт // International Journal of Open Information Technologies. 2021. № 8. С. 23-29. EDN: QIIHOL.
5. Сокуль М.В. Разработка методики выявления мошеннических транзакций по банковским картам на основе методов машинного обучения // Программные системы и вычислительные методы. 2026. № 1. С. 102-115. DOI: 10.7256/2454-0714.2026.1.78212 EDN: XZMICZ URL: https://nbpublish.com/library_read_article.php?id=78212
6. Тополян С.Г., Попов Д.И. Сравнительный анализ моделей искусственного интеллекта // Парадигма. 2025. № 6-1. С. 216-225. EDN: YQIAGJ.
7. Хамитов Р.М., Куценко С.М., Салтанаева Е.А. Применение методов машинного обучения для выявления мошенничества в банковских транзакциях // Экономика. Информатика. 2026. № 53(1). С. 111-121.
8. Yapp E.K.Y., Yeh H.-Y. An extensive experimental comparison of machine and deep learning methods for credit and bank fraud detection // Finance Research Letters. 2026. Vol. 88(C). Pp. 1-12. (In Engl.)
9. Huang H., Liu B., Xue X., Cao J., Chen X. Imbalanced credit card fraud detection data: A solution based on hybrid neural network and clustering-based undersampling technique // Applied Soft Computing. 2024. Pp. 1-8. (In Engl.)
10. Roseline J.F., Naidu G.B.S.R., Pandi V.S., Rajasree S.A., Mageswari D.N. Autonomous credit card fraud detection using machine learning approach // Computers and Electrical Engineering. 2022. Pp. 1-14. (In Engl.)
11. Chen Y., Zhao C., Xu Y., Nie C., Zhang Y. Deep Learning in Financial Fraud Detection: Innovations, Challenges, and Applications // Data Science and Management. 2025. Pp. 1-44. (In Engl.)
References
1
. Aldokhina, D.V. (2025). Application of artificial intelligence and machine learning methods for detecting financial fraud cases. Cifra: Computer Science and Informatics, 2(6), 1-4. https://doi.org/10.60797/COMP.2025.6.1
2
. Arkadyeva, O.G., & Petrov, A.V. (2025). Machine learning models as a tool for detecting suspicious bank transactions. Bulletin of Surgut State University, 13(3), 8-21. https://doi.org/10.35266/2949-3455-2025-3-1
3
. Ermolovskaya, O.Yu. (2025). Prevention of fraudulent transactions in the financial sector. Economic Security, 8(4), 923-942. https://doi.org/10.18334/ecsec.8.4.123240
4
. Osipova, T.A., Zaitsev, K.S., & Bifert, V.O. (2021). Application of machine learning algorithms to the problem of fraud detection in the use of plastic cards. International Journal of Open Information Technologies, 8, 23-29.
5
. Sokul', M.V. (2026). Development of a methodology for detecting fraudulent transactions using bank cards based on machine learning techniques. Software systems and computational methods, 1, 102-115. https://doi.org/10.7256/2454-0714.2026.1.78212
6
. Topolyan, S.G., & Popov, D.I. (2025). Comparative analysis of artificial intelligence models. Paradigm, 6-1, 216-225.
7
. Khamitov, R.M., Kutsenko, S.M., & Saltanaeva, E.A. (2026). Application of machine learning methods for detecting fraud in bank transactions. Economics and Informatics, 53(1), 111-121.
8
. Yapp, E.K.Y., & Yeh, H.-Y. (2026). An extensive experimental comparison of machine and deep learning methods for credit and bank fraud detection. Finance Research Letters, 88(C), 1-12.
9
. Huang, H., Liu, B., Xue, X., Cao, J., & Chen, X. (2024). Imbalanced credit card fraud detection data: A solution based on hybrid neural network and clustering-based undersampling technique. Applied Soft Computing, 1-8.
10
. Roseline, J.F., Naidu, G.B.S.R., Pandi, V.S., Rajasree, S.A., & Mageswari, D.N. (2022). Autonomous credit card fraud detection using machine learning approach. Computers and Electrical Engineering, 1-14.
11
. Chen, Y., Zhao, C., Xu, Y., Nie, C., & Zhang, Y. (2025). Deep Learning in Financial Fraud Detection: Innovations, Challenges, and Applications. Data Science and Management, 1-44.
Результаты процедуры рецензирования статьи
Рецензия выполнена специалистами Национального Института Научного Рецензирования по заказу ООО "НБ-Медиа".
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов можно ознакомиться здесь.
Представленная на рецензирование работа посвящена применению методов машинного обучения для выявления мошеннических транзакций в банковских системах. Предметом исследования выступает процесс построения предсказательной модели бинарной классификации операций и анализ влияния порогового значения вероятности на качество распознавания редкого класса в условиях выраженной несбалансированности данных. Выбор предмета представляется логически завершённым и соответствующим тематическому профилю журнала.
Методологическую основу составляет вычислительный эксперимент с использованием экосистемы Python и библиотек Pandas, Matplotlib и Scikit-learn. Автор последовательно проводит предварительную обработку данных, отбор и преобразование признаков (включая разложение временных меток на компоненты, кодирование One-Hot Encoding и Target Encoding), анализ корреляционных зависимостей, обучение ансамблевых моделей Random Forest и XGBoost с последующей оценкой по метрикам precision, recall, F1-score, ROC-AUC и PR-AUC. Вместе с тем методологическая часть описана излишне обобщённо: не приводятся источник и характеристика используемого набора данных (является ли он публичным или собственным, синтетическим или реальным), не указаны гиперпараметры моделей, не раскрыты конкретные методы балансировки классов, не описана процедура кросс-валидации и стратификация выборки. Формула (1) в тексте отсутствует, хотя на неё имеется ссылка. Эти аспекты требуют дополнительного раскрытия, поскольку без них результаты эксперимента не являются воспроизводимыми.
Актуальность темы не вызывает сомнений и обоснована автором убедительно. Рост объёма безналичных расчётов, усложнение мошеннических схем и неэффективность правилоориентированных систем мониторинга формируют устойчивый запрос на адаптивные методы выявления подозрительных операций, способные работать с большими объёмами и несбалансированными выборками.
Заявленная новизна состоит в анализе влияния настройки порога принятия решения на эффективность обнаружения редкого класса. Сам по себе подход к оптимизации порога классификации не является принципиально новым в задачах антифрод-анализа, поэтому формулировку научной новизны рекомендуется уточнить и усилить за счёт демонстрации авторских решений: например, предложить методику выбора оптимального порога, основанную на компромиссе между recall и стоимостью ложных срабатываний, либо обосновать критерий выбора порога, отличающийся от стандартных.
Структура работы соответствует традиционной для научной публикации схеме: введение, материалы и методы, результаты, обсуждение, заключение. Стиль изложения научный, однако нуждается в редакторской правке. В тексте встречаются опечатки («использвоанием», «машиного»), а также рассогласование форм («очищенную и преобразованную совокупность признаков, наилучшим образом подходящей»). Во введении тезис о том, что современное развитие банковского сектора сопровождается ростом объёма операций, дважды повторяется в близкой формулировке. Главное содержательное замечание относится к разделу «Результаты»: в нём отсутствуют конкретные численные значения метрик для сравниваемых моделей и для различных значений порога. Утверждения о том, что «XGBoost показал более высокие значения метрик» и что «recall и F1-score были более устойчивы», не подкреплены ни таблицами, ни графиками вида precision-recall или ROC-кривых. Без количественной аргументации выводы носят описательный характер и не могут быть верифицированы читателем. Рекомендуется привести сводную таблицу метрик для обеих моделей при стандартном и подобранном порогах, а также включить визуализацию зависимости recall, precision и F1-score от значения порога. Раздел «Обсуждение» в текущей версии в значительной мере повторяет содержание раздела «Результаты», тогда как от него ожидается более глубокая интерпретация причин различий в поведении моделей и сопоставление с результатами цитируемых работ.
Список литературы включает тринадцать источников, в нём представлены как русско-, так и англоязычные публикации, преимущественно последних лет, что отвечает требованиям актуальности. В то же время отдельные позиции (источники, посвящённые экспертным системам выбора стратегии обучения и адаптивному тестированию на основе нечёткой логики) слабо связаны с тематикой выявления мошеннических транзакций и выглядят как избыточные включения. Рекомендуется заменить их на работы по методам балансировки выборок (SMOTE, undersampling, cost-sensitive learning) и по интерпретируемости моделей в антифрод-системах.
В работе практически отсутствует содержательная полемика с другими исследователями: ссылки на источники приводятся преимущественно в констатирующем ключе. Рекомендуется усилить аналитическую часть, сопоставив полученные результаты с количественными результатами работ, упомянутых в библиографии, особенно с зарубежными публикациями, посвящёнными сравнению методов глубокого и классического машинного обучения для задачи fraud detection.
Статья посвящена важной и востребованной проблеме, опирается на адекватный методический инструментарий и в целом соответствует тематическому профилю издания. Полученные качественные выводы о преимуществе XGBoost над Random Forest в условиях несбалансированных данных и о существенном влиянии порогового значения согласуются с современными представлениями в данной области. Работа может представлять интерес для специалистов в области финансовых технологий, разработчиков систем антифрод-мониторинга, исследователей в области прикладного машинного обучения, а также для преподавателей соответствующих дисциплин. Вместе с тем в текущем виде статья нуждается в существенной доработке: требуется привести количественные результаты эксперимента, раскрыть источник и характеристики данных, конкретизировать процедуры балансировки и подбора гиперпараметров, восстановить пропущенную формулу, провести стилистическую и техническую правку текста, а также уточнить формулировку научной новизны. После внесения указанных изменений работа может быть рекомендована к публикации.
QR код для проверки
подлинности рецензии

Результаты процедуры повторного рецензирования статьи
Рецензия выполнена специалистами Национального Института Научного Рецензирования по заказу ООО "НБ-Медиа".
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов можно ознакомиться здесь.
Представленная на повторное рецензирование работа посвящена применению методов машинного обучения для выявления мошеннических транзакций в банковских системах. Предметом исследования выступает процесс построения предсказательной модели бинарной классификации операций и анализ влияния порогового значения вероятности на качество распознавания редкого класса в условиях выраженной несбалансированности данных. Выбор предмета представляется логически завершённым и соответствующим тематическому профилю журнала «Программные системы и вычислительные методы».
Методологическую основу составляет вычислительный эксперимент, реализованный средствами экосистемы Python с использованием библиотек Pandas, Matplotlib и Scikit-learn. Автор последовательно выполняет предварительную обработку данных, проверку их качества, исключение неинформативных и константных признаков, преобразование временных меток в составные компоненты, кодирование категориальных переменных посредством сочетания методов One-Hot Encoding и Target Encoding, анализ корреляционных зависимостей с целью устранения избыточности признакового пространства, а также построение ансамблевых моделей Random Forest и градиентного бустинга XGBoost с последующей оценкой по метрикам precision, recall, F1-score, ROC-AUC и PR-AUC. Корректно учитывается дисбаланс классов посредством взвешивания и подбора параметра scale_pos_weight, что согласуется с принятыми в литературе подходами для задач антифрода. Достаточно подробно описаны гиперпараметры обеих моделей и схема стратифицированного разбиения выборки в соотношении восемьдесят к двадцати, что обеспечивает воспроизводимость основных вычислительных процедур.
Актуальность исследования не вызывает сомнений и обоснована автором убедительно. Стремительный рост объёмов безналичных расчётов, усложнение и постоянная эволюция мошеннических сценариев, а также ограниченные возможности традиционных правилоориентированных систем мониторинга формируют устойчивый научно-практический запрос на адаптивные методы выявления подозрительных операций, способные эффективно работать с большими объёмами и существенно несбалансированными выборками. Тематика статьи органично встраивается в современную проблематику обеспечения экономической безопасности банковского сектора и поддержки принятия решений в подразделениях комплаенса кредитных организаций.
Научная новизна работы определяется разработкой и апробацией подхода к выбору порогового значения классификации в задаче выявления мошеннических транзакций в условиях несбалансированных данных. Предложенный подход основан на совместном анализе зависимостей метрик precision, recall и F1-score от величины порога с последующим выбором значения, обеспечивающего обоснованный компромисс между полнотой выявления мошенничества и допустимым уровнем ложноположительных срабатываний с учётом специфики антифрод-систем. Показано, что применение алгоритма XGBoost в сочетании с настройкой порога обеспечивает более высокую устойчивость модели к редкому классу по сравнению с Random Forest, что представляет самостоятельную методическую ценность и может быть использовано при проектировании производственных решений.
Стиль изложения соответствует жанру научной статьи. Текст характеризуется ясностью, логической последовательностью рассуждений и аккуратностью используемой терминологии. Структура работы традиционна для эмпирических исследований и включает введение с постановкой проблемы и формулировкой целей, раздел материалов и методов, изложение и интерпретацию результатов, обсуждение с сопоставлением полученных данных с известными зарубежными и отечественными исследованиями, а также заключение с обобщающими выводами. Содержание раздела результатов проиллюстрировано таблицей значений ключевых метрик для обеих моделей при стандартном и подобранном порогах, что наглядно подтверждает основные выводы автора. Аргументация ограниченной эффективности Random Forest и преимуществ XGBoost в задачах с выраженной несбалансированностью классов представлена корректно и согласуется со сложившимися в литературе представлениями.
Библиография работы является достаточной для раскрытия рассматриваемой темы и включает тринадцать источников, среди которых представлены как отечественные публикации последних лет, так и зарубежные работы, индексируемые в международных базах. После доработки в библиографическое описание добавлены идентификаторы цифровых объектов, диапазоны страниц и коды цитирования национальной системы, что заметно повысило формальное качество справочного аппарата и облегчает читателю проверку и обращение к первоисточникам. Источники охватывают как современные исследования по обнаружению финансового мошенничества и сравнению методов машинного и глубокого обучения, так и более ранние работы по экспертным системам и адаптивным алгоритмам, что обеспечивает преемственность научного контекста.
Апелляция к оппонентам реализована в разделе обсуждения, где автор корректно сопоставляет полученные результаты с данными, представленными в зарубежных и отечественных исследованиях по обнаружению финансового мошенничества. Отмечается, что наблюдаемые ограничения по полноте и F1-score для мошеннического класса согласуются с результатами других авторов при работе с сильно несбалансированными данными, а зафиксированное преимущество градиентного бустинга над ансамблями на решающих деревьях подтверждается рядом сравнительных исследований. Подобная форма дискуссии способствует объективной интерпретации полученных результатов и встраиванию работы в актуальный научный контекст.
Выводы автора логически вытекают из проведённого исследования и подтверждаются полученными количественными результатами. Сформулированные положения о необходимости совместного использования методов машинного обучения и настройки порогового значения для повышения эффективности выявления мошеннических транзакций в условиях несбалансированных данных представляются обоснованными и практически значимыми. Работа представляет интерес для широкой читательской аудитории журнала, включая исследователей в области интеллектуального анализа данных и прикладной статистики, специалистов по разработке антифрод-систем и систем противодействия отмыванию денежных средств, а также сотрудников подразделений информационной и экономической безопасности кредитных организаций.
С учётом изложенного представленная статья соответствует требованиям, предъявляемым к научным публикациям, обладает выраженной актуальностью, элементами научной новизны и практической значимостью, а внесённые автором изменения устранили ранее отмеченные замечания по оформлению справочного аппарата. Рекомендую статью к публикации в журнале «Программные системы и вычислительные методы».
QR код для проверки
подлинности рецензии

|
 Рус
Рус









