|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Скляр А.Я. Модели и алгоритмы нелинейного регрессионного анализа временных рядов // Программные системы и вычислительные методы. 2025. № 3. С. 115-128. DOI: 10.7256/2454-0714.2025.3.75317 EDN: OPDYKY URL: https://nbpublish.com/library_read_article.php?id=75317
Модели и алгоритмы нелинейного регрессионного анализа временных рядов
Скляр Александр Яковлевич
кандидат технических наук
доцент; кафедра прикладная математика; Российский технологический университет (МИРЭА)
119602, Россия, г. Москва, Вернадского, 78
Sklyar Alexander Yakovlevich
PhD in Technical Science
Associate Professor; Department of Applied Mathematics; Russian Technological University (MIREA)
78 Vernadsky Street, Moscow, 119602, Russia

|
askliar@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2025.3.75317
EDN:
OPDYKY
Дата направления статьи в редакцию:
27-07-2025
Дата публикации:
03-10-2025
Аннотация:
Анализ данных, описывающих те или иные объекты и процессы предназначен, прежде всего, для нахождения зависимостей внутри них и выявления динамики их развития. Целями анализа и прогнозирования является подготовка материалов для принятия обоснованных решений. В данной работе рассматриваются этапы, методы и алгоритмы проведения анализа, направленные на получение, в первую очередь, функциональных зависимостей, пригодных не только для описания, но и прогнозирования поведения изучаемых объектов и процессов. Сам анализ рассматривается как многоэтапный процесс, включающий подготовку данных, выявление и удаление по возможности шума в данных, нахождение долговременного тренда, выявление колебательной составляющей, периодичности колебаний, оценку динамики амплитуд колебаний, оценка точности возможной аппроксимации процесса и возможности его прогнозирования с учетом уровня зашумленности данных. Предложен ряд процедур, обеспечивающих обоснованную проверку гипотез о ходе процессов и получение аналитических, в том числе и дифференциальных зависимостей на основе методов оптимизации подбора параметров нелинейных зависимостей. Рассмотренные методы позволяют проводить достаточно объективный анализ данных и создают условия для построения обоснованного прогноза. Проведен численный анализ по данным многолетней статистики динамики производства. Научная новизна исследования заключается в разработке методики декомпозиции процесса на трендовые и колебательные компоненты. В отличие от большинства существующих исследований анализа динамики процессов большое внимание уделяется учету и оценке уровня шума с определением пределов точности получаемых результатов и, тем более, прогнозов, что позволяет избегать необоснованных выводов и решений и построения «слишком» точных результатов на основе недостаточно точных исходных данных, исходя из требований гладкости функции при имеющемся уровне шума. Использование функций ограниченного роста и выявление точек смены тренда позволяет проводить корректное качественное долгосрочное прогнозирование без необоснованного предсказания катастрофического хода изучаемого процесса. Полученные результаты позволяют получить аналитическое выражение изучаемых, прежде всего экономических процессов, что позволяет не только аппроксимировать поведение процесса, но и выявлять его физическую сущность и, соответственно использовать полученные решения на целый класс процессов аналогичной природы.
Ключевые слова:
анализ данных, временной ряд, удаление шума, долгосрочный тренд, оценка точности, аппроксимация данных, нелинейная регрессия, проверка гипотез, ограниченный рост, анализ колебаний
Abstract: The analysis of data describing certain objects and processes is primarily intended to find dependencies within them and to identify the dynamics of their development. The goals of analysis and forecasting are to prepare materials for making informed decisions. This work examines the stages, methods, and algorithms of conducting analysis aimed at obtaining, primarily, functional dependencies that are suitable not only for description but also for predicting the behavior of the studied objects and processes. The analysis itself is viewed as a multi-stage process that includes data preparation, identifying and removing noise from the data as much as possible, finding a long-term trend, identifying oscillatory components, periodicity of fluctuations, assessing the dynamics of amplitude fluctuations, evaluating the accuracy of possible approximations of the process, and the feasibility of forecasting considering the level of data noise. A number of procedures are proposed to ensure a reasoned verification of hypotheses about the course of processes and to obtain analytical, including differential dependencies based on optimization methods for parameter fitting of nonlinear dependencies. The methods discussed allow for conducting a sufficiently objective data analysis and create conditions for building a reasonable forecast. A numerical analysis was conducted based on multi-year statistics of production dynamics. The scientific novelty of the study lies in the development of a methodology for decomposing the process into trend and oscillatory components. Unlike most existing studies of process dynamics analysis, significant attention is given to accounting for and assessing the noise level by determining the limits of accuracy of the obtained results and, moreover, forecasts, which helps avoid unfounded conclusions and decisions and the construction of "overly" precise results based on insufficiently precise initial data, taking into account the requirements of function smoothness at the existing noise level. The use of limited growth functions and the identification of trend shift points allows for correct qualitative long-term forecasting without unreasonable predictions of a catastrophic course of the studied process. The results obtained allow for an analytical expression of the studied processes, primarily economic ones, which not only enables the approximation of the process behavior but also reveals its physical essence, thus allowing the application of these solutions to a whole class of processes of a similar nature.
Keywords:
data analysis, time series, noise removal, long-term trend, accuracy estimation, data approximation, nonlinear regression, hypothesis testing, imited growth, oscillation analysis
Введение
Анализ статистических данных предназначен, прежде всего для выявления внутренних зависимостей. Применительно к данным, представленным во временном ряде – это выявление динамики развития характеристики процесса, описываемого этими данными. Большинство процессов, прежде всего экономических, являются непрерывными. Их характеристики могут меняться в достаточно широких, но всегда ограниченных диапазонах. Сами данные во временных рядах, описывающих процесс дискретны и подвержены влиянию случайных факторов начиная с ошибок измерения и различных внешних неконтролируемых возмущений. В этих условиях задача анализа распадается на ряд поэтапно решаемых подзадач.
Выделим основные этапы:
удаление шума (случайных возмущений);
нахождение долговременного тренда;
выявление колебательной составляющей;
оценка динамики амплитуд колебаний;
оценка точности возможной аппроксимации процесса и возможности его прогнозирования с учетом уровня зашумленности данных; следует всегда помнить, что точность прогноза ни при каких обстоятельствах не может быть выше уровня шума.
В случаях, когда процессы описываются набором дискретных состояний, обработка должна строится на выделении точек перехода с использованием иного инструментария. К основным методам, широко использующимся в настоящее время, относятся методы, основанные на использовании деревьев решений [1, 2], кластерного анализа [3], нейронных сетей [4]. Основы этих методов описаны и в учебной литературе, например, в учебнике М.Ю. Мошкова (Мошков М. Ю. Деревья решений. Теория и приложения. Нижний Новгород. Изд. Нижегородского ун. 1994. 176 с.).
Оценка и удаление шума в данных
Анализ и обработка зашумленных данных вызывает значительные трудности. Возникает задача устранения, по возможности, такого шума. Для устранения такого шума используются различные методы сглаживания, такие, как методы скользящей средней, экспоненциального сглаживания и др. (Эконометрика. Учебник / Под ред. Елисеевой И. И. — 2-е изд. — М.: Финансы и статистика, 2006. — 576 с. — ISBN 5-279-02786-3), а также методы полиномиального сглаживания, прежде всего Савицкого – Галея [5].
Обозначим значения аргумента (временные отрезки) через xi, соответствующие им наблюдаемые значения через yi, предполагаемую функцию «истинной» зависимости – f(x). Далее будем рассматривать случай, когда исходные данные задаются с постоянным шагом h и xi+1=xi+h.
Тогда наблюдаемые данные можно представить в виде yi=f(xi)+si, где si – шум.
Функцию f(x) будем считать k раз дифференцируемой, тогда ее производная может быть вычислена как
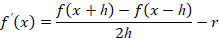
Здесь r – систематическая ошибка
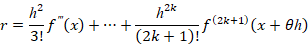
Взяв значения функции в нескольких последовательных точках, можно показать, что всегда существует набор величин λi таких, что
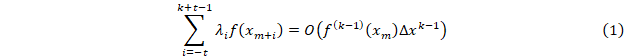
В частности, при равномерном шаге при k=3, 4, 5 получим наборы λi (1, -2, 1), (-1, 3, -3, 1), (1, -4, 6, -4, 1) соответственно, что соответствует численным выражениям для 2, 3 и 4 производных [6, 7]. Отклонение от 0 таких сумм для любых слабо осциллирующих функций пренебрежимо мало.
Рассмотрим
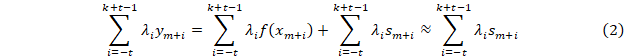
Величины si – независимые случайные числа с нулевым математическим ожиданием. Среднеквадратичное значение σ для s можно получить
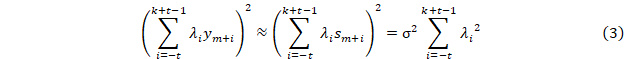
При 5 точечной схеме это дает с равномерным шагом это дает значение 70σ2. Просуммировав эти величины по n точкам ряда, получим значение D, где D=70nσ2, откуда σ2=D/70n. Таким образом получаем объективную оценку уровня шума в данных.
Определить значения si, а значит и fi можно решением
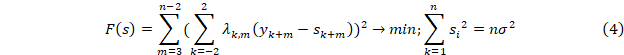
Полученное решение дает сглаженный ряд, представляющий максимально близкую к исходному гладкую функцию, что позволяет использовать не только входные данные, но и их производные [6, 7].
Нахождение долговременного тренда
Говоря о тренде u(t), обычно понимают некоторое усреднение данных f(t) в той или иной мере приближающееся к конструкции 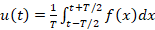 . Здесь T задает промежуток усреднения, определяя характер тренда. На практике обычно применяют методики скользящего среднего или многократного скользящего выравнивания. Проблемой подобных методов помимо их зависимости от способа выравнивания является отсутствие сколько-нибудь явной аналитической зависимости. . Здесь T задает промежуток усреднения, определяя характер тренда. На практике обычно применяют методики скользящего среднего или многократного скользящего выравнивания. Проблемой подобных методов помимо их зависимости от способа выравнивания является отсутствие сколько-нибудь явной аналитической зависимости.
Альтернативой такому подходу является проверка соответствия исходных данных некоторой теоретической кривой u(x, p1, …, pk) с набором параметров. Задача состоит в подборе этих параметров на основе, например, метода наименьших квадратов.
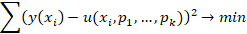
Эта задача сводится к решению системы уравнений

В общем случае это система из k нелинейных уравнений, решение которых достаточно затруднительно. Система становится линейной только, когда функция u линейна по всем своим параметрам, например, когда u полином от x. Такая конструкция может с какой угодно точностью аппроксимировать исходные данные, но «дальний» прогноз на ее основе теряет смысл, поскольку он в зависимости от знака старшего коэффициента стремится либо к +∞, либо к +∞.
В ряде случаев преобразование системы координат (анаморфоза) позволяет выстроить исследуемые данные в линейную зависимость. Например, переход в логарифмические или полулогарифмические координаты линеаризует экспоненциальную, степенную и логарифмическую зависимости [8]. Последнее, к сожалению, возможно лишь когда целевая переменная не меняет свой знак.
Более эффективные результаты можно получить, если данные исходного ряда дифференцируемы, что может быть достигнуто, например, описанной выше процедурой удаления шума.
Для природных и, прежде всего, экономических процессов, функционирующих в относительно постоянных условиях, характерно асимптотическое стремление к некоторому уровню. Такие процессы естественным образом описываются моделями ограниченного роста. Рассмотрим такие процессы и методы определения их параметров.
Дифференциальные методы.
Экспоненциальное приближение к постоянной y=a+be-kt.
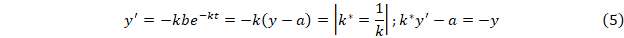
Здесь параметры a и k* входят линейно и, подставляя исходные значения ряда в y и y´ методом наименьших квадратов находим требуемые параметры, причем знак и наличие колебаний в исходных данных не являются препятствием. Зная параметры a и k из соотношения y=a+be-kt находим параметр b.
Гиперболическое приближение к постоянной y=a+b/(x+c).
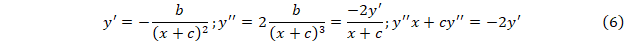
Отсюда последовательно находим параметр c и далее a и b.
Либо без использования высших производных
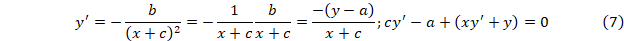
Модель Гомперца y’/y=ae-kx; 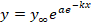
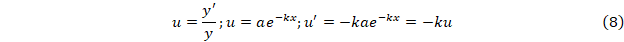
Отсюда последовательно находим параметр k и далее a, и y∞.
Сигмоидальные модели 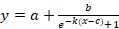 ; ; 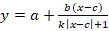 ; ; 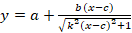 ; ; 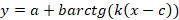 и т.п. с тем свойством, что их графики обладают центральной симметрией относительно точки (c,y(c)). и т.п. с тем свойством, что их графики обладают центральной симметрией относительно точки (c,y(c)).
Точку c можно найти минимизацией f(c)
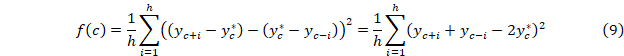
В качестве yc* можно принять yc*=yc или предпочтительней 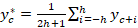
После этого переход к z=y-yc* сигмоиду с нулем в точке c.
Так для классической экспоненциальной сигмоиды получим z=bth(k(x-c)).
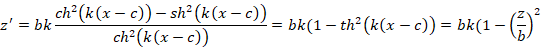
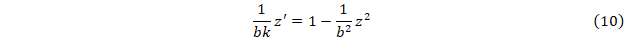
И введя p=1/bk, q=1/b2 получим 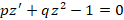 . Откуда методом наименьших квадратов находятся параметры p и q и, следовательно a и b. . Откуда методом наименьших квадратов находятся параметры p и q и, следовательно a и b.
Интегральные методы.
В ряде случаев дифференциальные методы плохо применимы из-за высокого уровня погрешностей при вычислении производных, особенно высших порядков. В то же время аналогичный подход вполне реализуем при замене производных соответствующими интегралами.
Рассмотрим экспоненциальное приближение к постояннойy=a+be-kt.
Введем
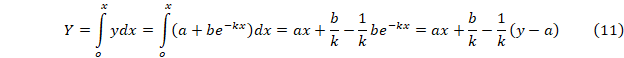
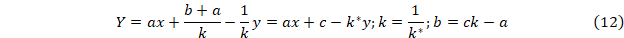
Получение Y численным интегрированием исходных данных не вызывает никаких проблем и легко реализуется стандартными методами, например средствами Excel и следом выполнив нахождение параметров a, k и b методом наименьших квадратов получим требуемую линию тренда.
Аналогично можно построить и алгоритмы для других гипотез для нахождения линий тренда. Существенным здесь является тот факт, что данная методика применима для любых данных вне зависимости от наличия в них колебаний.
Характеристические показатели
Параметры моделей ограниченного роста могут быть оценены на основе набора характеристических интегральных показателей выдвигаемой гипотезы.
Экспоненциальное приближение к постоянной
Для унификации расчетов линейно преобразуем интервал изменения аргумента к интервалу [0, 1].
Простая экспонента
y= be-kt (t⸦[0, 1])
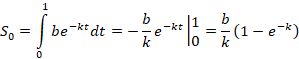
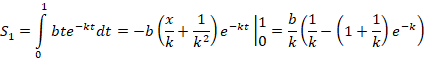
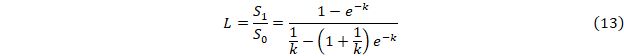
Значения L(k) табулируются. После этого нахождение k(L) не вызывает проблем. Далее находим 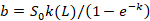
Смещенная экспонента
y= a+be-kt (t⸦[0, 1])
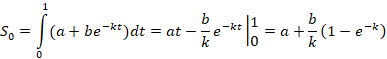
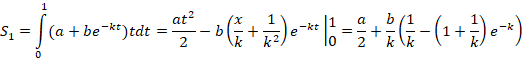
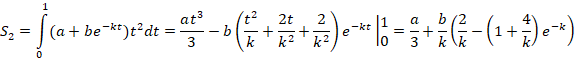
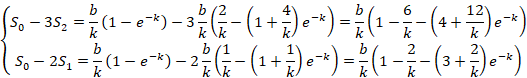
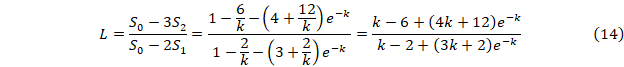
Значения L(k) табулируются. После этого нахождение k(L) не вызывает проблем. Далее находим
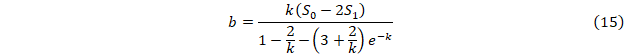
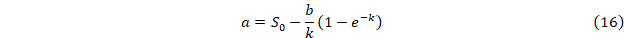
Модель Гомперца y’/y=ae-kx; 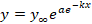 . .
u=y’/y=ae-kx представляет собой простую экспоненту, а ее параметры без дальнейшего дифференцирования получаются по приведенному выше методу.
Сигмоидальные модели
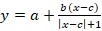 ; ; 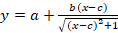 ; ;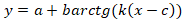
Находим точку центральной симметрией сигмоидальной модели (c,y(c)) yc* и переходим к z=y-yc* – сигмоиде с нулем в точке c.
Для первого случая получим
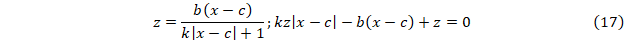
Поскольку z и c известны, то методом наименьших квадратов находятся параметры b и k.
Для второго случая получим
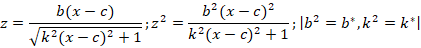
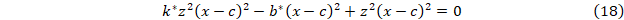
Поскольку z и c известны, то методом наименьших квадратов находятся параметры b* и k* и, следовательно b и k.
Для третьего случая получим
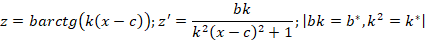
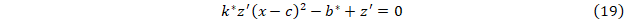
Поскольку z, z’ и c известны, то методом наименьших квадратов находятся параметры b* и k* и, следовательно b и k.
Нахождение технического тренда
Рассматриваемые выше методы выявления тренда основаны на проверке их соответствия исходных данным выдвинутым ранее некоторым гипотезам. Альтернативой являются чисто технические методы удаления колебаний (варианты скользящей средней). Пусть y(t)=f(t)+g(t), где g(x) описывает колебательный процесс с периодом T вокруг 0, а f(t) – тренд, тогда можно ввести понятие T-тренда u(t).
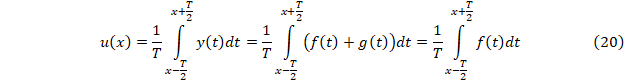
И принять функцию u(x) за линию тренда. При этом необходимо помнить, что u(t) дает систематическое отклонение от f(t).
Представим
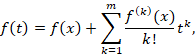
Тогда
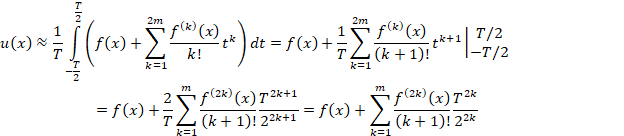
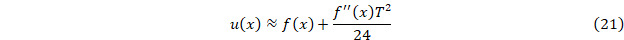
Для оценки среднего значения f’’’(t) введем функцию вида ax2+bx+c аппроксимирующую исходную на интервале x-T/2≤t≤x-T/2. Она имеет постоянную вторую производную, значение которой будем принимать за среднее значение f’’(t).
Ортогональные полиномы до второй степени на интервале [-h, h] (h=T/2) имеют вид: p0=1; p1=t; p2=t2-h2/3.
Коэффициент при второй степени аппроксимирующего полинома
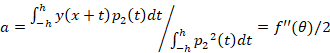
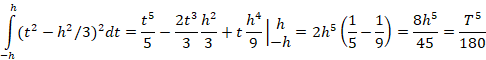
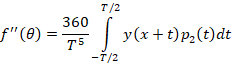
Соответственно, исправленное значение
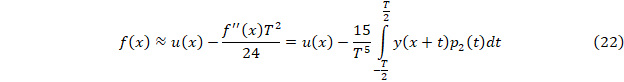
Нахождение колебаний
Колебания можно рассматривать, как разность между исходными данными и трендом. Анализ колебаний включает выявление их частотных и амплитудных составляющих, однако амплитуда колебаний может естественным образом зависеть от величины измеряемой характеристики.
Альтернативой для выявления колебательных процессов являются методы удаления тренда. В основе их лежит построение функции u(f(t)), которая поглощает трендовую составляющую f(t) при сохранении ее колебательной составляющей [9, 10]. Примером такой функции может служить u(t)=f(t+h)-2f(t)+f(t-h). В самом деле, пусть на некотором интервале a≤е≤b представима в виде f(t)=(pt+q)+g(x), где g(x) описывает колебательный процесс вокруг 0. В этом случае u(t)=f (t+h)-2f(t)+f(t-h)=g(t+h)-g(t)+g(t-h) и u(t) не содержит трендовой составляющей, но сохраняет колебательные составляющие. Еще один вариант функции u(t)=f(t+h) f(t-h)/ f(t) 2-1 или 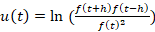 , обеспечивающий удаление экспоненциального тренда. Отметим, что последний вариант сводится к линейному переходом в полулогарифмические координаты F(t)=ln(f(t). , обеспечивающий удаление экспоненциального тренда. Отметим, что последний вариант сводится к линейному переходом в полулогарифмические координаты F(t)=ln(f(t).
Определение периодов колебаний функции u(t) может быть выполнено, например, на основе быстрого преобразования Фурье или с использованием сдвиговой функции Альтера – Джонсона.
К сожалению, функции u(t) заметно искажают амплитуды колебательных процессов. Пусть f(t)=(pt+q)+g(x)=(pt+q)+Asin(2πt/T+φ). В этом случае
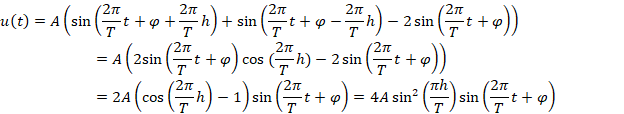
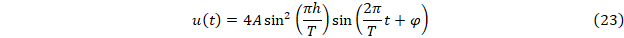
Таким образом амплитуда колебаний B(T)=4Asin2(πh/T) при T<<h превращается в практически генератор случайных чисел, при T>>h стремится к 0. В этих условиях достоверное определение периодов колебаний возможно только для ограниченного диапазона длин этих периодов.
Пусть исходный процесс описывается функцией y(t), тренд – функцией U(t), тогда колебательная составляющая представима в виде Φ(t)=y(t)-U(t). Для оценки тренда амплитуды можно воспользоваться функцией Z(t)=| Φ(t) |, усреднение которой дает величину, пропорциональную амплитуде (или Z(t)=Φ2(t) пропорциональную квадрату амплитуды). Для получения собственно линии тренда можно воспользоваться предварительным ее усреднением по периоду T колебаний Z(t), либо по представлению 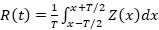 , либо используя алгоритм удаления шума, описанный выше, где за величинy шума s(t) в точке t принимается , либо используя алгоритм удаления шума, описанный выше, где за величинy шума s(t) в точке t принимается 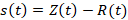 . В последнем случае не происходит явная потеря концов интервала, хотя точность на концах, конечно, получается невысокой. Полученное выражение A(t) пригодно для аналитической аппроксимации либо непосредственно, либо как отношение A(t)/U(t), либо как сумма вида a+bU(t), где a и b некоторые константы, а U(t) – тренд характеристики. После этого колебание Φ(t) представимо в виде Φ(t)=AT(t) φ(t). . В последнем случае не происходит явная потеря концов интервала, хотя точность на концах, конечно, получается невысокой. Полученное выражение A(t) пригодно для аналитической аппроксимации либо непосредственно, либо как отношение A(t)/U(t), либо как сумма вида a+bU(t), где a и b некоторые константы, а U(t) – тренд характеристики. После этого колебание Φ(t) представимо в виде Φ(t)=AT(t) φ(t).
Здесь AT(t) – тренд амплитуды, а φ(t) представляет колебания с почти постоянной амплитудой и может быть относительно успешно представлена аналитическим выражением.
Функция, описывающая развитие процесса во времени роста (темпов развития) в принятых обозначениях представима в виде
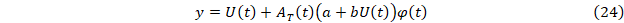
или для темпов
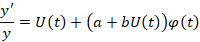
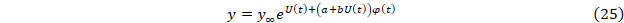
Анализ колебательной составляющей φ(t) можно проводить на основе ее представления в виде суммы нескольких простых периодических колебаний. Периоды этих колебаний можно определить на основе применения дискретного преобразования Фурье (ДПФ), нахождения минимумов сдвиговой функции или простым подбором гармонических колебаний.
Для сдвиговой функции (функция Джонсона) [9] p(τ) определяются ее локальные минимумы, соответствующие предполагаемым почти периодам в исходном временном ряде. Значения p(τ) определяются из
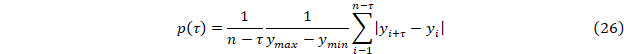
Подбор гармонических колебаний осуществляется минимизацией функции R(T1, T2…) по параметрам T1, T2. R(T1, T2…) из минимизации
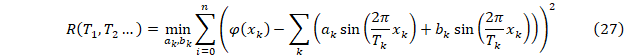
В ряде случаев, например при анализе темпов развития процесса, то есть величин вида y’/y с несимметричными колебаниями вокруг 0 прямое нахождение тренда, отличного от линейного может оказаться затруднительным. В этом случае оказывается целесообразным предварительное определение технического тренда c усреднением по периоду колебаний, а затем построение уже на нем аналитического тренда в соответствии с выдвинутой гипотезой.
Численная реализация
Рассмотрим предлагаемые методы на примере – статистике производства товаров длительного пользования в США за 1947-2016 годы (Bureau of Economic Analysis, United States Department of Commerce. https://www.bea.gov/sites/default/files/2018-04/GDPbyInd_VA_1947-2017.xlsx). Соответствующие данные представлены на рисунке 1. Полученная удалением шума кривая является гладкой и пригодна для обработки с использованием дифференциальных соотношений.
На рисунке 2 приведены 3 кривые, описывающие фактические темпы развития производства, темпы с удалением периодической составляющей (с почти периодом в 10,5 лет) и убывающим экспоненциальным трендом. Сразу заметим, что при переходе от абсолютных величин к темпам явно видна циклическая составляющая с почти периодом ≈10,5 лет (циклы Жигляра – Маркса). Удаление этой составляющей показывает наличие и более длинных циклов (похожих на Кондратьевские, хотя и более коротких). Тренд близок к убывающему экспоненциальному. Последнее говорит, что процесс развивается по схеме близкой к «испорченной» модели Гомперца, где в экспоненту включается колебательная составляющая.
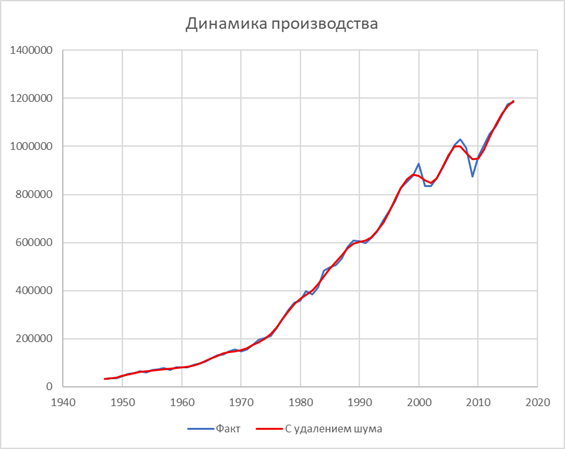
Рисунок 1. Динамика производства товаров длительного пользования в США за 1947-2016 годы (фактическая и с удалением шума).
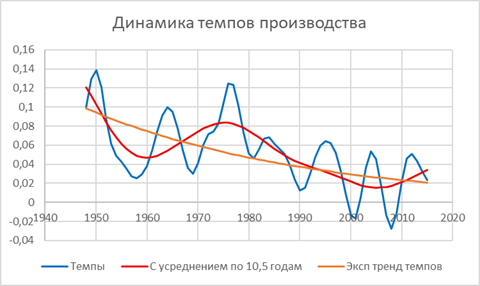
Рисунок 2. Динамика темпов развития производства с выделением среднесрочного тренда с удалением коротких колебаний и долговременного апериодического экспоненциального тренда.
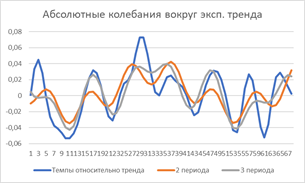
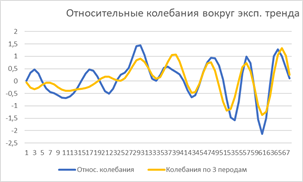
На рисунке 3 представлены абсолютные и относительные колебания темпов относительно апериодического тренда и результаты попыток их аппроксимации суммой 2 и 3 гармонических колебаний.
Рисунок 3. Пример разложения абсолютных и относительных колебаний темпов относительно апериодического тренда в виде суммы гармоник.
Аппроксимация, «похожа» на исходные колебания, но не более того. Это отражает тот факт, что колебания являются именно почти периодическими и строгих периодов не имеют. Последнее принципиально ограничивает возможности долговременного прогноза в силу неопределенности конкретных сроков наступления тех или иных событий и соответствующих им значений, сохраняя лишь качественный ход процесса (почти как у Нострадамуса), давая почву для «оптимистических» и «пессимистических» прогнозов.
Заключение
Рассмотренные методы позволяют проводить достаточно объективный анализ данных и создают условия для построения обоснованного прогноза. Проведен численный анализ по данным многолетней статистики динамики производства. Научная новизна исследования заключается в разработке методики декомпозиции процесса на трендовые и колебательные компоненты. В отличие от большинства существующих исследований анализа динамики процессов большое внимание уделяется учету и оценке уровня шума с определением пределов точности получаемых результатов и, тем более, прогнозов, что позволяет избегать необоснованных выводов и решений и построения «слишком» точных результатов на основе недостаточно точных исходных данных, исходя из требований гладкости функции при имеющемся уровне шума. Использование функций ограниченного роста и выявление точек смены тренда позволяет проводить корректное качественное долгосрочное прогнозирование без необоснованного предсказания катастрофического хода изучаемого процесса. Полученные результаты позволяют получить аналитическое выражение изучаемых процессов на основе статистических данных, представленных в виде временных рядов что позволяет не только аппроксимировать поведение процесса, но и выявлять его физическую сущность и, соответственно использовать полученные решения на целый класс процессов аналогичной природы. Предлагаемые методы и алгоритмы ориентированы, прежде всего на анализ и прогнозирование динамики экономических процессов, а также ряда природных процессов, например, метеорологических, подверженных влиянию различных, в том числе и случайных факторов.
Библиография
1. Breiman L., Friedman J., Olshen R.A., Stone C.J. Classification and Regression Trees. New York: Imprint Chapman and Hall/CRC, 2017. – 368 p. DOI: https://doi.org/10.1201/9781315139470. (First published 1984)
2. Дюран Б., Оделл П. Кластерный анализ. М.: Статистика, 1977. – 128 с.
3. Рашид Тарик. Создаем нейронную сеть. М.: Диалектика-Вильямс, 2023. – 272 с.
4. Мошков М. Ю. Оценки глубины деревьев решений над конечными двузначными системами проверок. // Математические вопросы кибернетики. Вып. 7. М.: Физматлит, 1998. С. 161-168. URL: http://library.keldysh.ru/mvk.asp?id=1998-161.
5. Savitzky A., Golay M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Analytical Chemistry. 1964. 36(8). P. 1627-1639.
6. Скляр А.Я. Анализ и устранение шумовой компоненты во временных рядах с переменным шагом // Кибернетика и программирование. 2019. № 1. С. 51-59. DOI: 10.25136/2644-5522.2019.1.27031 URL: https://nbpublish.com/library_read_article.php?id=27031
7. Скляр А. Я. Математическое моделирование экономических процессов на основе принципа максимума полезности. М.: РТУ МИРЭА, 2021. – 180 с.
8. Кузьмин В.И., Самохин А.Б., Гадзаов А.Ф., Чердынцев В.В. Модели и методы определения параметров нелинейных процессов. М.: Московский технологический университет (МИРЭА), 2016. – 148 с.
9. Johnson M. Correlations of cycles in weather, solar activity, geomagnetic values and planetary configurations. San Francisco: Phillips and Van Orden, 1944. – 122 p.
10. Кузьмин В.И., Самохин А.Б. Почти периодические функции с трендом. Вестник МГТУ МИРЭА. 2015. № 4(9). Т. 2. С. 105-107. EDN: VHIYPJ
References
1
. Breiman, L., Friedman, J., Olshen, R. A., & Stone, C. J. (2017). Classification and regression trees. Chapman and Hall/CRC. https://doi.org/10.1201/9781315139470 (First published 1984).
2
. Duran, B., & Odell, P. (1977). Cluster analysis. Statistika.
3
. Rashid, T. (2023). Creating a neural network. Dialectics-Williams.
4
. Moshkov, M. Y. (1998). Estimates of the depth of decision trees over finite binary systems of checks. In Mathematical questions of cybernetics (Vol. 7, pp. 161-168). Fizmatlit. http://library.keldysh.ru/mvk.asp?id=1998-161
5
. Savitzky, A., & Golay, M. J. E. (1964). Smoothing and differentiation of data by simplified least squares procedures. Analytical Chemistry, 36(8), 1627-1639.
6
. Sklyar, A. (2019). Analysis and elimination of noise components in time series with variable pitch. Cybernetics and programming, 1, 51-59. https://doi.org/10.25136/2644-5522.2019.1.27031
7
. Sklyar, A. Y. (2021). Mathematical modeling of economic processes based on the principle of maximum utility. RTU MIREA.
8
. Kuzmin, V. I., Samokhin, A. B., Gadzaov, A. F., & Cherdyncev, V. V. (2016). Models and methods for determining parameters of nonlinear processes. Moscow Technological University (MIREA).
9
. Johnson, M. (1944). Correlations of cycles in weather, solar activity, geomagnetic values, and planetary configurations. Phillips and Van Orden.
10
. Kuzmin, V. I., & Samokhin, A. B. (2015). Almost periodic functions with a trend. Bulletin of MGTU MIREA, 4(9), 105-107. EDN: VHIYPJ.
Результаты процедуры рецензирования статьи
Рецензия выполнена специалистами Национального Института Научного Рецензирования по заказу ООО "НБ-Медиа".
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов можно ознакомиться здесь.
Предметом исследования в рецензируемом исследовании выступают методы анализа временных рядов, в статье акцент сделан на нелинейные регрессионные модели.
Методология работы базируется на применении различных подходов для аппроксимации трендов, статистического сглаживания (полиномиальные фильтры, оценка уровня шума через дисперсию), гармонического анализа для выделения периодических компонент, а также визуализации данных.
Актуальность исследования авторы связывают с необходимостью анализа статистических данных для выявления внутренних зависимостей.
Научная новизна исследования заключается в обобщении сведений о моделях и алгоритмах нелинейного регрессионного анализа временных рядов; полученное в результате исследования приращение научного знаниями позиционируется авторами как разработка «методики декомпозиции процесса на трендовые и колебательные компоненты».
Структурно в тексте выделены следующие озаглавленные разделы и подразделы: Введение, Оценка и удаление шума в данных, Нахождение долговременного тренда, Дифференциальные методы (Экспоненциальное приближение к постоянной, Гиперболическое приближение к постоянной, Модель Гомперца, Сигмоидальные модели), Интегральные методы, Характеристические показатели (Экспоненциальное приближение к постоянной), Нахождение технического тренда, Нахождение колебаний, Численная реализация, Заключение и Библиография.
В статье рассмотрены такие этапы анализа временных рядов как удаление шума (методы Савицкого–Галея, скользящие средние), выделение тренда (экспоненциальные, гиперболические, сигмоидальные модели), анализ колебательных компонент (разложение Фурье, сдвиговые функции). Авторами освещены как классические подходы (метод наименьших квадратов), так и оригинальные алгоритмы, например, интегральные методы для оценки параметров тренда. Численная реализация рассмотренных в статье методов проиллюстрирована авторами на примере – статистике производства товаров длительного пользования в США за 1947-2016 годы. Предлагаемые методы и алгоритмы ориентированы на анализ и прогнозирование динамики экономических процессов, а также ряда природных процессов, например, метеорологических, подверженных влиянию различных, в том числе и случайных факторов.
Библиографический список включает 10 источников – научные публикации российских и зарубежных авторов по рассматриваемой теме на русском языке и иностранных языках. В тексте публикации имеются адресные отсылки к списку литературы, подтверждающие наличие апелляции к оппонентам.
Из резервов улучшения работы стоит отметить, что авторами не выполнены требования принятых редакцией Правил оформления списка литературы, в соответствии с которыми «рекомендованный объем списка литературы для оригинальной научной статьи – не менее 20 источников». Оформление интервалов, которые в представленных материалах отражаются в виде отсылок к списку литературы ввиду использования квадратных скобок, например «к интервалу [0, 1]» (с использованием для написания "[0, 1]" в качестве шрифта верхнего индекса).
Тема статьи актуальна, материал соответствует тематике журнала «Программные системы и вычислительные методы», отражает результаты проведенного исследования, может вызвать интерес у читателей, рекомендуется к опубликованию.
QR код для проверки
подлинности рецензии

|
 Рус
Рус