|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Труб И.И.
Об аппроксимации выходных данных вероятностной модели иерархических битовых индексов
// Программные системы и вычислительные методы.
2018. № 4.
С. 102-113.
DOI: 10.7256/2454-0714.2018.4.27809 URL: https://nbpublish.com/library_read_article.php?id=27809
Об аппроксимации выходных данных вероятностной модели иерархических битовых индексов
Труб Илья Иосифович
кандидат технических наук
ведущий инженер-программист, ООО "Исследовательский центр Samsung"
127018, Россия, г. Москва, ул. Двинцев, 12, оф. C
Trub Ilya
PhD in Technical Science
Senior Software Engineer, Samsung Research Center Ltd.
127018, Russia, Moscow, ul. Dvintsev, 12, of. C

|
itrub@yandex.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2018.4.27809
Дата направления статьи в редакцию:
27-10-2018
Дата публикации:
10-01-2019
Аннотация:
Предметом исследования является вероятностная модель иерархических битовых индексов баз данных. Объектом исследования являются выходные данные модели - трехпараметрическое дискретное распределение количества индексов для реализации запросов к базе данных, параметризуемое интенсивностью занесения записей в базу, средней длиной запроса и размером крупного индекса. Автор рассматривает такие аспекты темы как выбор гипотезы из известных теоретических распределений, методика проверки гипотезы, подбор функций для приближения зависимости математического ожидания от третьего параметра, подбор функции для приближения зависимости точки минимума математического ожидания по третьему параметру от первых двух. Исследование таких зависимостей объясняется тем, что оптимальный выбор именно третьего параметра является целью проектировщика, а первые два - это исходные данные модели. Методологией исследования являются методы математической статистики, в частности, оценка параметров и критерий Пирсона проверки гипотез, методы построения наилучших приближений, в частности, метод наименьших квадратов, теория кривых третьего порядка. Основные выводы проведенного исследования: наилучшей аппроксимацией для исследуемого семейства распределений является распределение Пойа; наилучшими приближениями для зависимости математического ожидания от третьего параметра являются модель Бэкона-Уаттса и теплоемкостная модель. Особым вкладом автора в исследование темы является вывод эмпирической формулы, имеющей практическое значение. Она позволяет проектировщику на основе первых двух параметров сразу, без использования громоздких расчетов по модели, получить приближенное оптимальное значение третьего параметра и построить таким образом индекс базы данных оптимального размера. Новизна исследований заключается в получении приближенных зависимостей для нового вида распределения, которое невозможно описать замкнутой формулой.
Ключевые слова:
иерархические битовые индексы, дискретное распределение вероятностей, распределение Пойа, отрицательное биномиальное распределение, модель Бэкона-Уаттса, теплоемкостная модель, кривые третьего порядка, анализ выходных данных, метод наименьших квадратов, степенная функция
Abstract: The subject of the study is a probabilistic model of hierarchical bit indexes of databases. The object of the study is the output of the model — a three-parameter discrete distribution of the number of indexes for implementing queries to the database, parametrized by the intensity of recording records in the database, the average query length, and the size of a large index. The author considers such aspects of the topic as the choice of a hypothesis from known theoretical distributions, a method for testing a hypothesis, selection of functions for approximating the dependence of the expectation on the third parameter, selection of a function for approximating the dependence of the minimum point of the expectation for the third parameter from the first two. The study of such dependencies is explained by the fact that the optimal choice of the third parameter is the goal of the designer, and the first two are the initial data of the model. The methodology of the research is the methods of mathematical statistics, in particular, the estimation of parameters and the Pearson criterion of testing hypotheses, methods for constructing the best approximations, in particular, the method of least squares, the theory of curves of the third order. The main conclusions of the study: the best approximation for the studied family of distributions is the Polya distribution; The best approximations for the dependence of the expectation on the third parameter are the Bacon-Watts model and the heat capacity model. A special contribution of the author to the study of the topic is the derivation of an empirical formula that has practical significance. It allows the designer on the basis of the first two parameters at once, without using cumbersome calculations on the model, to obtain an approximate optimal value of the third parameter and thus construct an index of the database of the optimal size. The novelty of the research lies in obtaining approximate dependencies for a new type of distribution that cannot be described by a closed formula.
Keywords: hierarchical bitmap indexes, discrete probability distribution, Polia distribution, negative binomial distribution, Bacon-Watts model, heat capacity model, third order curves, output analysis, least square method, power function
Введение
В работе [10] была предложена аналитическая вероятностная модель, позволяющая количественно оценить эффективность иерархических битовых индексов баз данных, где индексируемым свойством предполагался момент времени возникновения некоего события в общем потоке событий. Модель основывалась на следующих входных данных:
· Распределение 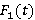 интервала времени между двумя последовательными событиями входного потока; интервала времени между двумя последовательными событиями входного потока;
· Распределение 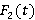 длины интервала времени для клиентского запроса на выборку данных; длины интервала времени для клиентского запроса на выборку данных;
· Иерархия битовых индексов по времени, заданная упорядоченным множеством натуральных чисел 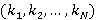 , где , где 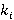 – кратность i-го индекса по отношению к (i-1)-му. – кратность i-го индекса по отношению к (i-1)-му.
Для возможности построения модели были приняты следующие ограничения:
· Распределение 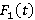 – экспоненциальное с параметром λ; – экспоненциальное с параметром λ;
· Левая граница интервала запроса совпадает с началом N-го - самого крупного индекса (например, с началом часа).
Выходными данными модели является распределение вероятностей  для дискретной случайной величины Y – количества индексов, необходимых для вычисления запроса, и соответственно, ее среднего значения как показателя эффективности использования данной иерархии индексов. Практическая же цель - нахождение иерархии, минимизирующей для дискретной случайной величины Y – количества индексов, необходимых для вычисления запроса, и соответственно, ее среднего значения как показателя эффективности использования данной иерархии индексов. Практическая же цель - нахождение иерархии, минимизирующей 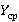 . Модификация модели, учитывающая различные алгоритмы обработки индексов при обслуживании запроса, рассмотрена в [12]. . Модификация модели, учитывающая различные алгоритмы обработки индексов при обслуживании запроса, рассмотрена в [12].
В построенной модели вероятности вычисляются в виде достаточно сложной комбинации рядов и интегралов, где суммирование ведется по определенным образом усеченному множеству разложений числа на слагаемые. Вид этих формул в [10] исключает возможность суммирования рядов и получения результата в замкнутом виде. Таковой был получен в [9] лишь в случае полного отсутствия иерархии индексов. Данное обстоятельство является практически повсеместным в классической теории массового обслуживания и не должно удивлять. В самом деле, если обратиться к классическому труду [6], можно увидеть, что замкнутые решения удается получить только для систем M/M/1, M/M/n, M/Er/1 и т.п. Уже для системы M/G/1 согласно формуле Поллачека-Хинчина распределение числа заявок в системе может быть получено только в виде производящей функции, в которую входит преобразование Лапласа распределения длительности обслуживания, и для всех таких распределений, за исключением самых простых, обратить производящую функцию аналитически невозможно. Но из формулы Поллачека-Хинчина можно, во всяком случае, вычислить математическое ожидание и последующие моменты искомой случайной величины. В нашем же случае нельзя сделать и этого – всегда требуется численный прогон модели. Даже в простейшем примере, когда N=1, а распределение – тоже экспоненциальное.
Такая ситуация мало полезна архитектору БД, у которого может и не оказаться в наличии программного обеспечения, реализующего модель или времени и желания разбираться, как ей пользоваться. Полезной для него была бы пусть приближенная, но простая рабочая формула, справедливая хотя бы для указанного простейшего случая, с помощью которой он мог бы быстро оценить по значениям λ и μ оптимальный размер грубого индекса и заложить в архитектуру БД построение этого индекса. Чтобы получить такую формулу, требуется провести квалифицированный численный анализ выходных данных модели. Именно такой анализ и является предметом исследования настоящей работы. В нем для N=1 и экспоненциального поставлены и рассмотрены следующие задачи:
· аппроксимация известными теоретическими распределениями;
· аппроксимация функции 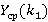 при фиксированных λ и μ; при фиксированных λ и μ;
· аппроксимация функции двух переменных 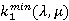 , которую определим как значение , которую определим как значение 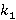 , доставляющее минимум функции при заданных λ и μ. В дальнейшем будем ссылаться на нее как на функцию Ω(λ, μ). , доставляющее минимум функции при заданных λ и μ. В дальнейшем будем ссылаться на нее как на функцию Ω(λ, μ).
Эти задачи разбираются соответственно в первом, втором и третьем разделе работы. В четвертом разделе рассматривается возможность аппроксимации выходных данных модели на множестве кривых третьего порядка. В заключении дана общая оценка полученных результатов.
1. Аппроксимация распределения 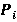
Характерной особенностью 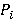 , которую можно заметить в [10], является короткий промежуток возрастания, максимум и далее затяжное убывание до нуля с перегибом. Кроме того, значение , которую можно заметить в [10], является короткий промежуток возрастания, максимум и далее затяжное убывание до нуля с перегибом. Кроме того, значение 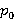 не зависит от значения крупного индекса и согласно [9] вычисляется по формуле не зависит от значения крупного индекса и согласно [9] вычисляется по формуле
|
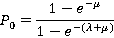
|
(1)
|
Существует множество работ, в которых изучается тот или иной частный способ подбора распределения, такие работы регулярно появляются и сейчас [13]. Но, тем не менее, в общем случае для подбора известного распределения не обойтись без хорошего справочника, в котором можно было бы попытаться найти распределение, визуально похожее на исследуемое. Таких справочников, на удивление, не так уж много. В сети пользуется популярностью [17], но для реальной исследовательской задачи его полнота оказывается недостаточной. На взгляд автора, вне конкуренции находится отечественный источник [2] как по полноте охвата материала, так и по глубине его изложения и способу структурирования. Поиск возможных визуальных аналогов в этом справочнике приводит к двум распределениям-кандидатам: отрицательное биномиальное первого типа и распределение Пойа второго типа. Рассмотрим примененную технику оценивания параметров для каждого из них.
1.1. Отрицательное биномиальное распределение (ОБР).
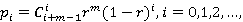
где m – натуральное число, 0<r<1. Математическое ожидание равно
|
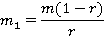
|
(2)
|
Параметр r согласно [2] определяется путем численного решения уравнения
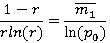
где 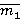 - выборочная оценка математического ожидания, - выборочная оценка математического ожидания, 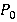 в нашем случае можно оценить с помощью (1). Поскольку в нашем случае можно оценить с помощью (1). Поскольку 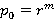 , находим оценку , находим оценку 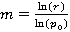 , которую затем округляем до ближайшего целого. После чего согласно (2) пересчитываем , которую затем округляем до ближайшего целого. После чего согласно (2) пересчитываем 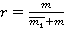 . .
1.2. Распределение Пойа.
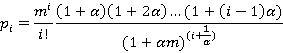
где m>0, 0<α<1, m>1/(1-α). Математическое ожидание равно m. Параметр α определяется из численного решения уравнения
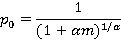
Нетрудно видеть, что оба распределения в вырожденных случаях сводятся к геометрическому распределению, т.е. тому, каким согласно [9] описывается распределение при отсутствии индексов: первое – при m=1, второе – при α=1. Общие соображения говорят в пользу того, что распределение Пойа больше подходит для нашей цели, т.к. для ОБР оценку параметра m приходится округлять до ближайшего целого, что существенно снижает точность аппроксимации. Кроме того, один из параметров распределения Пойа является одновременно и математическим ожиданием (ведь исследование именно этой величины интересует нас в прикладном аспекте), а в ОБР оно вычисляется через параметры.
На рис.1 изображен типичный график распределения P(i), рассчитанного с помощью модели [10] (красная линия), его аппроксимация ОБР (фиолетовая) и распределением Пойа (желтая). Параметры модели: λ=0.033, μ=0.001, 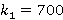 . Рассчитанные параметры ОБР m=3, r=0.3, распределения Пойа m=7.019, α=0.354. . Рассчитанные параметры ОБР m=3, r=0.3, распределения Пойа m=7.019, α=0.354.
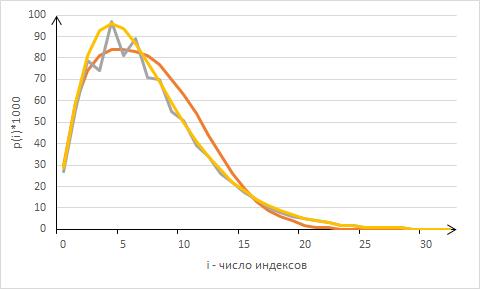
Рис. 1. Распределение для λ=0.033, μ=0.001, и его аппроксимации
Для этого и большого количества других совокупностей исходных данных гипотеза о соответствии распределениям ОБР и Пойа согласуется с критерием Пирсона [3, 5], если предварительно искусственно сгруппировать значения . Можно ли предположительно считать задачу решенной? Обратимся к словам авторитетного российского специалиста [4]: “Хорошо проработанных теоретически и проверенных на практике методов определения функции распределения (плотности) при обработке выборок большого объема нет. К сожалению, применение классических методов также затруднительно, поскольку на таком большом объеме данных с огромным количеством пиков чрезвычайно трудно предложить гипотезу о распределении, и с большой долей вероятности она будет ошибочной. В таких выборках законы распределения абсолютно нетривиальны, скорее всего это будут комбинации сразу нескольких законов на различных участках графика”. В полной мере эти слова применимы и здесь – в общем случае гипотеза, увы, ошибочна.
Чтобы убедиться в этом, следует взять не усредненный, а «пиковый» набор исходных данных, например, резко увеличить соотношение между параметрами. Для графика на рис.2 λ=0.98, μ=0.001, 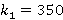 . Рассчитанные параметры ОБР m=2, r=0.034, распределения Пойа m=57.3, α=0.489. . Рассчитанные параметры ОБР m=2, r=0.034, распределения Пойа m=57.3, α=0.489.
Рисунок говорит сам за себя, и критерий Пирсона в данном случае гипотезу, разумеется, не подтверждает. Искомое распределение на среднем участке не является константой, но очень медленно меняется в достаточной широкой окрестности точки максимума. Можно сказать, что здесь вероятности гораздо более тонким слоем «размазаны» на своем носителе, для этого достаточно обратить внимание на диапазоны оси абсцисс на рис. 1 и 2. Таким образом, гипотеза справедлива лишь частично, а в целом исследуемое распределение и в самом деле следует признать нетривиальным, не
Рис. 2. Распределение для λ=0.89, μ=0.001, и его аппроксимации
описываемым на всем пространстве своих параметров каким-либо уже известным законом.
2. Аппроксимация зависимости 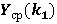
Как следует из [10], особенностями этой зависимости является быстрое убывание в левой ветви, затем следует затяжной минимум, в районе которого функция очень медленно меняется, и медленный гладкий рост в правой ветви с асимптотическим стремлением к значению для 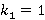 . Такое поведение можно попытаться описать следующим уравнением: . Такое поведение можно попытаться описать следующим уравнением:
|
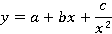
|
(3)
|
которое среди различных моделей аппроксимации известно как heat capacity model. Наилучшие параметры a, b и c рассчитываются методом наименьших квадратов. Действительно, эта модель подходит для случаев, когда 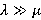 . По мере же уменьшения отношения λ к μ, точность аппроксимации уравнением (3) снижается, зато всё более подходящей становится модель двухфазного перехода Бэкона-Уаттса, впервые описанная в [15] и развитая в [18]. Она имеет вид: . По мере же уменьшения отношения λ к μ, точность аппроксимации уравнением (3) снижается, зато всё более подходящей становится модель двухфазного перехода Бэкона-Уаттса, впервые описанная в [15] и развитая в [18]. Она имеет вид:
|
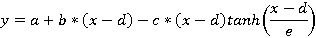
|
(4)
|
где 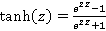 – гиперболический тангенс. В свою очередь, при эта модель описывает искомую зависимость плохо. На рис.3 изображены данные для λ=0.98, μ=0.001 (красная линия). Желтым цветом показана наилучшая кривая (3) с коэффициентами a=20.6, b=0.13, c=6206.5. Здесь же фиолетовым цветом показана наилучшая кривая (4) с коэффициентами a=-7.8, b=1.36, c=1.2, d=-133.2, e=147.2. Нетрудно видеть, что точность приближения с помощью (3) выше. – гиперболический тангенс. В свою очередь, при эта модель описывает искомую зависимость плохо. На рис.3 изображены данные для λ=0.98, μ=0.001 (красная линия). Желтым цветом показана наилучшая кривая (3) с коэффициентами a=20.6, b=0.13, c=6206.5. Здесь же фиолетовым цветом показана наилучшая кривая (4) с коэффициентами a=-7.8, b=1.36, c=1.2, d=-133.2, e=147.2. Нетрудно видеть, что точность приближения с помощью (3) выше.
Картина меняется на рис.4. Здесь показаны данные для λ=0.03, μ=0.001 (красная линия). Желтым цветом показана наилучшая кривая (3) с коэффициентами a=13.2,
b=-0.004, c=838.8, фиолетовым цветом - наилучшая кривая (4) с коэффициентами a=2.3, b=5.7, c=5.7, d=-269.2, e=112.5. Здесь очевидна более высокая точность для (4). Применение обеих моделей логически оправдано, исходя из вида аппроксимируемого семейства кривых, но в разных точках (λ;μ) наилучшее приближение дает либо одна, либо другая их них.
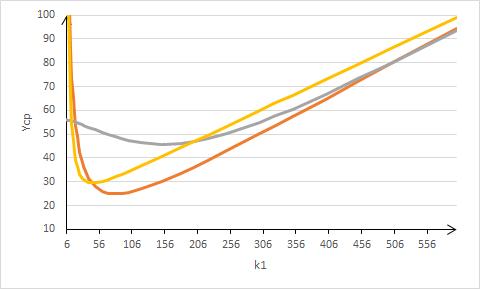
Рис. 3. 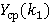 для λ=0.98, μ=0.001 и его аппроксимации для λ=0.98, μ=0.001 и его аппроксимации
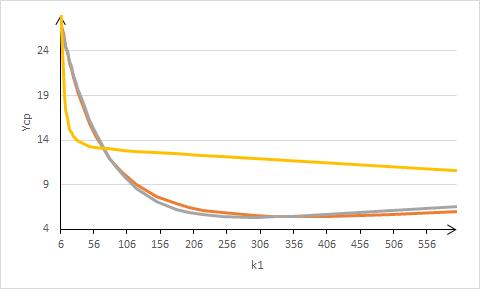
Рис. 4. для λ=0.03, μ=0.001 и его аппроксимации
Таким образом, все итоговые рассуждения предыдущего раздела работы остаются справедливы – единой функции нет. Но даже если бы она и была, например, та же модель heat capacity, для придания ей прикладной ценности понадобилось бы еще найти устойчивые зависимости всех ее трех параметров от λ и μ (а в модели Бэкона-Уаттса – для пяти параметров), что заведомо имело бы весьма небольшие шансы на успех. Поэтому понижаем размерность задачи еще на один уровень (соответственно повышаем уровень детализации) и переходим к следующему разделу.
3. Аппроксимация зависимости Ω(λ,μ)
После выполнения всех прогонов модели для табулирования данной зависимости производим подбор семейства функций. И здесь как для зависимости от λ при различных μ, так и для зависимости от μ при различных λ в качестве наилучшего приближения устойчиво показывает себя степенная функция с показателем степени, очень близким к
-0.5. На рис.5 показана зависимость от λ для μ=0.002, на рис.6 – зависимость от μ для λ=0.03. Это наблюдение позволяет искать аппроксимацию в виде
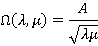
где A=const. Разумеется, это предположение будет справедливо только в том случае, если оценки значения A, вычисленные при подборе наилучшей зависимости указанного вида для широкого диапазона различных значений λ и μ, будут флуктуировать в каком-то достаточно ограниченном диапазоне. Многочисленные расчеты подтверждают это – во всех без исключения экспериментах округление полученного значения A до ближайшего целого дает 2 (полученный диапазон для A варьировался от 1.68 до 2.42). Таким образом, можно выписать эмпирическую формулу
|
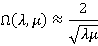
|
(5)
|
Это и есть тот результат, который можно предложить инженеру БД для оценки оптимального размера крупного индекса. Что можно сказать о нем? Опытные
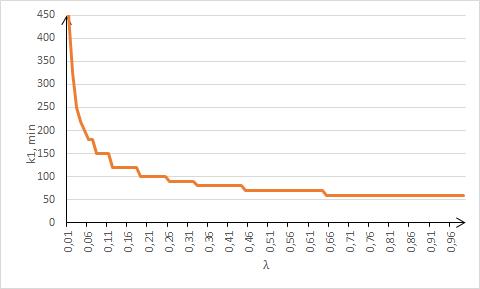
Рис.5. Зависимость Ω(λ), μ=0.002
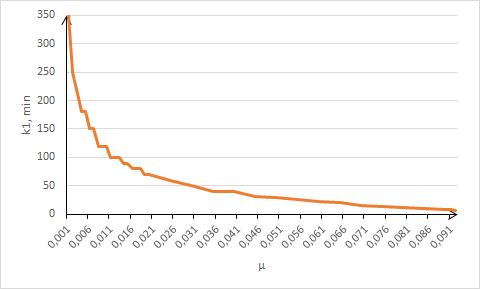
Рис.6. Зависимость Ω(μ ), λ=0.03
специалисты в области методов оптимизации хорошо понимают разницу между понятиями «оптимальное решение» и «хорошее начальное приближение», между тем как новички зачастую обманчиво принимают второе за первое. Как же формально можно описать слово «хорошее»? Такое решение:
1) не является, строго говоря, точкой минимума;
2) качественно, в разы уменьшает значение минимизируемой функции по сравнению с «естественным» начальным приближением (например, равным нулю или единице);
3) любое другое начальное приближение не дает качественного, скачкообразного эффекта по сравнению с данным;
4) в большинстве случаев, если не требуется очень высокая точность, приемлемо для практического применения.
Формула (5) для рассматриваемой задачи является именно таким хорошим начальным приближением, особенно, с учетом того, что в районе точке минимума функция меняется очень медленно. Проиллюстрируем это конкретными цифрами. При λ=0.033, μ=0.001 значение, вычисленное по формуле (5) дает 348, и это практически идеальное приближение к настоящей точке минимума. При λ=0.99, μ=0.007 значение, вычисленные по формуле (5) дает 24 (значение функции в нем 9.6), истинная же точка минимума равна 28 (значение функции – 9.4). Для практики применения в БД такое различие не играет никакой роли, если учесть, что при отсутствии индексов (т.е. при ) 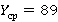 . Таким образом, (5) является вполне удовлетворительной, можно даже сказать, хорошей заменой использования трудоемкой математической модели в инженерных расчетах. Инженеру лишь необходимо оценить нагрузку, под которой будет работать база данных, в виде входящих в эту формулу параметров. . Таким образом, (5) является вполне удовлетворительной, можно даже сказать, хорошей заменой использования трудоемкой математической модели в инженерных расчетах. Инженеру лишь необходимо оценить нагрузку, под которой будет работать база данных, в виде входящих в эту формулу параметров.
4. Аппроксимация кривыми третьего порядка
Большую вариабельность для подбора приближений дает множество кривых третьего порядка, хотя этот подход и не имеет большого распространения. Из вузовского курса аналитической геометрии хорошо известна классификация кривых второго порядка, но их вариабельность – три типа – слишком мала. Кривые третьего порядка не входят в вузовский курс, а между тем – это богатый и содержательный мир, который может предложить заинтересованному исследователю много интересного. Чтобы подобрать к своей экспериментальной кривой подходящий аналог среди кривых третьего порядка опять-таки требуется хороший справочник. Из отечественных известны как классические труды [7],[8], так и изданный уже в компьютерную эру [14] (ему автор и отдает предпочтение), из зарубежных – [16] и [19]. Любопытно было бы поискать среди разнообразия кривых третьего порядка визуальные аналоги для и . И таковые обнаруживаются.
похоже на серпантину Ньютона. Это кривая, описываемая уравнением 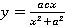 . Такое приближение мало чем полезно в массовом случае, но если обобщить уравнение до вида . Такое приближение мало чем полезно в массовом случае, но если обобщить уравнение до вида
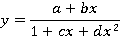
то метод метод наименьших квадратов дает довольно правдоподобные приближения. На рис. 7 показано приближение для μ=0.005, λ=0.07, 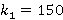 (красная линия) наилучшей серпантиной Ньютона (фиолетовая линия), где a=0.09, b=-0.0048, c=-0.314, d=0.046. (красная линия) наилучшей серпантиной Ньютона (фиолетовая линия), где a=0.09, b=-0.0048, c=-0.314, d=0.046.
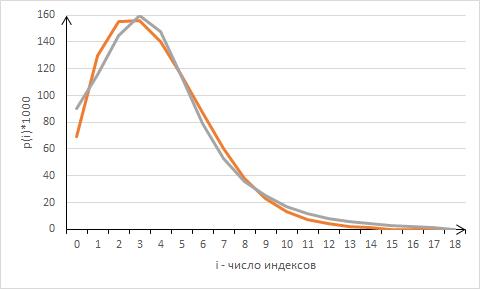
Рис.7. Приближение распределения серпантиной Ньютона.
Зависимости наилучшим образом соответствует по внешнему виду кривая Ролля, каноническое уравнение которой имеет вид 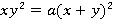 , откуда следует , откуда следует 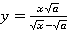 . Будем опять-таки искать приближение в обобщенном двухпараметрическом виде . Будем опять-таки искать приближение в обобщенном двухпараметрическом виде  . На рис. 8 показано приближение для μ=0.005, λ=0.5 (красная линия) наилучшей кривой Ролля (фиолетовая линия), где a=1.387, b=2.204. . На рис. 8 показано приближение для μ=0.005, λ=0.5 (красная линия) наилучшей кривой Ролля (фиолетовая линия), где a=1.387, b=2.204.
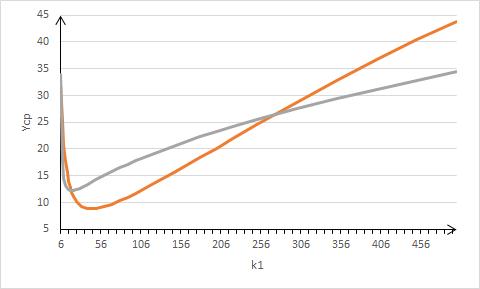
Рис.8. Приближение кривой Ролля.
Массовому применению метода, по-видимому, мешает тот же самый фактор – его точечность. Очень трудно построить аналитические зависимости для наилучших значений параметров этих кривых от входных прикладных параметров модели.
Заключение
Как писал в своем главном труде[1] классик отечественного моделирования Н.П.Бусленко “…метод статистического моделирования, как любой численный метод, обладает существенным недостатком: решение всегда носит частный характер. Оно соответствует фиксированным значениям параметров системы и начальных условий. Обычно для анализа система приходится многократно моделировать ее процесс функционирования, варьирую исходные данные задачи». Справедливо будет сказать, что эти слова могут служить эпиграфом к данной работе, как и то, что ее целью было частичное преодоление указанного недостатка.
Оценивая полученный основной результат – формулу (5) – выпишем еще раз все ограничения и приближения, принятые при его выводе.
Математическая модель:
· экспоненциальное распределение для . На самом деле входной поток может описываться другим распределением;
· экспоненциальное распределение для 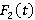 . На самом деле длина запроса может описываться другим распределением; . На самом деле длина запроса может описываться другим распределением;
· выполнение элементарного граничного условия. На самом деле левая граница интервала запроса может не совпадать с левой границей крупного индекса
Аппроксимация выходных данных:
· погрешность вычисления точки минимума по для функции 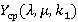 ввиду высокой трудоемкости вычисления этой функции в одной точке (λ, μ) – чем точнее мы хотим получить точку минимума, тем сильнее придется сгущать сетку вокруг нее; ввиду высокой трудоемкости вычисления этой функции в одной точке (λ, μ) – чем точнее мы хотим получить точку минимума, тем сильнее придется сгущать сетку вокруг нее;
· ограниченность области задания значений функции по той же причине – экспериментальная табуляция функции двух переменных далеко не одно и то же, что экспериментальная табуляция функции одной переменной;
· погрешность приближения указанной выше функции степенной функцией, т.е. непосредственно формулой (5). В силу двух предшествующих пунктов нет и не может быть стопроцентной уверенности в том, что наилучшие значения степеней в знаменателе - это 1/2, а наилучшее значение константы в числителе – 2.
Первая группа ограничений частично снимается заменой расчетов с помощью аналитической модели расчетами с помощью имитационной [11], вторая группа – экстенсивным путем, т.е. увеличением мощи вычислительного ресурса. Но с технической точки зрения вопрос состоит в том, какая точность нужна проектировщику. Если эффективность быстрого решения по формуле (5) представляется ему недостаточной, он может попробовать улучшить решение указанными выше способами. Но, как правило, для подавляющего большинства корпоративных приложений это не требуется – соображений, положенных в основу концепции хорошего начального приближения, оказывается вполне достаточно.
С математической точки зрения представляет интерес вопрос как будет выглядеть аналог формулы (5), когда одна или обе функции и далеки от экспоненциального распределения. Однако, для удовлетворения такого интереса в каждом конкретном случае, как уже было отмечено, требуется большой опыт, интуиция и недюжинное терпение вычислителя.
Библиография
1. Бусленко Н.П. Моделирование сложных систем. - М.: Наука, 1968. 356 с.
2. Вадзинский Р.Н. Справочник по вероятностным распределениям.-Санкт-Петербург, "Наука", 2001. 150 с.
3. Гмурман В.Е. Теория вероятностей и математическая статистика.-Москва, Высшая школа, 1997.-480 с.
4. Девятков Т. В. Некоторые вопросы создания систем автоматизации имитационных исследований // Прикладная информатика. 2010. № 5 (29). С. 102 – 116.
5. Елисеева И.И., Юзбашев М.М. Общая теория статистики. Учебник.-Москва, Финансы и статистика, 2004.-656 с.
6. Клейнрок Л. Теория массового обслуживания.-Л.: Машиностроение, 1979.-380 с.
7. Савелов А.А. Плоские кривые: семантика, свойства, применение.-Москва, Государственное издательство физико-математической литературы, 1960.-294 с.
8. Смогоржевский А.С., Столова Е.С. Справочник по теории плоских кривых третьего порядка.-Москва, Государственное издательство физико-математической литературы, 1961.-272 с.
9. Труб И.И. Аналитическое вероятностное моделирование bitmap-индексов // Программные системы и вычислительные методы. – 2016. – № 4. – С. 315-323. DOI: 10.7256/2305-6061.2016.4.2109
10. Труб И.И. Вероятностная модель иерархических индексов базы данных // Программные системы и вычислительные методы. — 2017.-№ 4.-С.15-31. DOI: 10.7256/2454-0714.2017.4.24437. URL: http://e-notabene.ru/ppsvm/article_24437.html
11. Труб И. И. Имитационное моделирование иерархических bitmap-индексов // Прикладная информатика. 2018. № 4 (76). С.53–69.
12. Труб И.И., Труб Н.В. Модель иерархических индексов баз данных с принятием решений и ее сравнение с минимаксной моделью // Программные системы и вычислительные методы. — 2018.-№ 1.-С.18-36. DOI: 10.7256/2454-0714.2018.1.25369. URL: http://e-notabene.ru/ppsvm/article_25369.html
13. Тырсин А.Н. Метод подбора наилучшего закона распределения непрерывной случайной величины на основе обратного отображения.-Вестник ЮУрГУ, серий "Математика. Механика. Физика", т.9, № 1, 2017. с.31-38.
14. Шикин Е.В., Франк-Каменецкий М.М. Кривые на плоскости и в пространстве.-Москва, Фазис, 1997.-336 с.
15. Bacon D.W., Watts D.G. Estimating the Transition between Two Intersecting Straight Lines.-Biometrika, vol. 58, no. 3, December, 1971. pp. 525-534.
16. Lockwood E.H. A Book of Curves.-Cambridge University Press, Great Britain, 1961. 210 p.
17. McLaughlin M.P. Compendium of Common Probability Distributions.-December, 2016. URL: www.causascientia.org/math-stat/Dists/Compendium.pdf
18. Walkowiak R., Kala R. Two-Phase Nonlinear Regression with Smooth Transition.-Communication in Statistics-Simulation and Computation, vol. 29, no. 2, January, 2000. pp. 385-397.
19. Yates R.C. Curves and Their Properties.-National Council of Teachers Mathematics, Washington, USA, 1974. 260 p
References
1. Buslenko N.P. Modelirovanie slozhnykh sistem. - M.: Nauka, 1968. 356 s.
2. Vadzinskii R.N. Spravochnik po veroyatnostnym raspredeleniyam.-Sankt-Peterburg, "Nauka", 2001. 150 s.
3. Gmurman V.E. Teoriya veroyatnostei i matematicheskaya statistika.-Moskva, Vysshaya shkola, 1997.-480 s.
4. Devyatkov T. V. Nekotorye voprosy sozdaniya sistem avtomatizatsii imitatsionnykh issledovanii // Prikladnaya informatika. 2010. № 5 (29). S. 102 – 116.
5. Eliseeva I.I., Yuzbashev M.M. Obshchaya teoriya statistiki. Uchebnik.-Moskva, Finansy i statistika, 2004.-656 s.
6. Kleinrok L. Teoriya massovogo obsluzhivaniya.-L.: Mashinostroenie, 1979.-380 s.
7. Savelov A.A. Ploskie krivye: semantika, svoistva, primenenie.-Moskva, Gosudarstvennoe izdatel'stvo fiziko-matematicheskoi literatury, 1960.-294 s.
8. Smogorzhevskii A.S., Stolova E.S. Spravochnik po teorii ploskikh krivykh tret'ego poryadka.-Moskva, Gosudarstvennoe izdatel'stvo fiziko-matematicheskoi literatury, 1961.-272 s.
9. Trub I.I. Analiticheskoe veroyatnostnoe modelirovanie bitmap-indeksov // Programmnye sistemy i vychislitel'nye metody. – 2016. – № 4. – S. 315-323. DOI: 10.7256/2305-6061.2016.4.2109
10. Trub I.I. Veroyatnostnaya model' ierarkhicheskikh indeksov bazy dannykh // Programmnye sistemy i vychislitel'nye metody. — 2017.-№ 4.-S.15-31. DOI: 10.7256/2454-0714.2017.4.24437. URL: http://e-notabene.ru/ppsvm/article_24437.html
11. Trub I. I. Imitatsionnoe modelirovanie ierarkhicheskikh bitmap-indeksov // Prikladnaya informatika. 2018. № 4 (76). S.53–69.
12. Trub I.I., Trub N.V. Model' ierarkhicheskikh indeksov baz dannykh s prinyatiem reshenii i ee sravnenie s minimaksnoi model'yu // Programmnye sistemy i vychislitel'nye metody. — 2018.-№ 1.-S.18-36. DOI: 10.7256/2454-0714.2018.1.25369. URL: http://e-notabene.ru/ppsvm/article_25369.html
13. Tyrsin A.N. Metod podbora nailuchshego zakona raspredeleniya nepreryvnoi sluchainoi velichiny na osnove obratnogo otobrazheniya.-Vestnik YuUrGU, serii "Matematika. Mekhanika. Fizika", t.9, № 1, 2017. s.31-38.
14. Shikin E.V., Frank-Kamenetskii M.M. Krivye na ploskosti i v prostranstve.-Moskva, Fazis, 1997.-336 s.
15. Bacon D.W., Watts D.G. Estimating the Transition between Two Intersecting Straight Lines.-Biometrika, vol. 58, no. 3, December, 1971. pp. 525-534.
16. Lockwood E.H. A Book of Curves.-Cambridge University Press, Great Britain, 1961. 210 p.
17. McLaughlin M.P. Compendium of Common Probability Distributions.-December, 2016. URL: www.causascientia.org/math-stat/Dists/Compendium.pdf
18. Walkowiak R., Kala R. Two-Phase Nonlinear Regression with Smooth Transition.-Communication in Statistics-Simulation and Computation, vol. 29, no. 2, January, 2000. pp. 385-397.
19. Yates R.C. Curves and Their Properties.-National Council of Teachers Mathematics, Washington, USA, 1974. 260 p
|
 Рус
Рус

















