|
Историческая информатика
Правильная ссылка на статью:
Гарскова И.М., Зуева В.А.
Многомерная нечеткая классификация в историко-типологическом исследовании: разработка и апробация новой версии программного продукта
// Историческая информатика.
2018. № 2.
С. 6-26.
DOI: 10.7256/2585-7797.2018.2.26871 URL: https://nbpublish.com/library_read_article.php?id=26871
Многомерная нечеткая классификация в историко-типологическом исследовании: разработка и апробация новой версии программного продукта
Гарскова Ирина Марковна
доктор исторических наук
доцент, Московский государственный университет им. М.В. Ломоносова (МГУ)
119607, Россия, г. Москва, ул. Ramenki, 31-253
Garskova Irina Markovna
Doctor of History
Associated professor, Lomonosov Moscow State University
119607, Russia, g. Moscow, ul. Ramenki st., 31-253, Ramenki st., 31-253, of. Ramenki st., 31-253

|
irina.garskova@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
Зуева Вероника Андреевна
инженер - вирусный аналитик, ООО "Доктор Веб"
119192, Россия, Москва область, г. Москва, ул. Ломоносовский Проспект, 27к4, оф. Е253
Zueva Veronika Andreevna
Engineer - virus analyst, "Doctor Web" LLC
119192, Russia, Moscow oblast', g. Moscow, ul. Lomonosovskii Prospekt, 27k4, of. E253
|
|
bakerst221b.uk@gmail.com
|
|
 |
|
DOI: 10.7256/2585-7797.2018.2.26871
Дата направления статьи в редакцию:
14-07-2018
Дата публикации:
02-08-2018
Аннотация:
Задачей данного исследования является разработка новой версии про-граммы многомерной нечеткой классификации для OC Windows на основе алгоритма FuzzyClass, созданного на кафедре исторической информатики МГУ. Предыдущая версия программы, FuzzyClass1 создана более 30 лет назад и до сих пор востребована в историко-типологических исследованиях во многом потому, что методы нечеткой классификации пока отсутствуют в большинстве стандартных статистических пакетов. Потребность в разработке новой версии программы связана с тем, что FuzzyClass1 была создана в операционной системе DOS, что затрудняет ее адаптацию для ОС Windows, Mac и др. Кроме того, существует необходимость сделать программу более простой, дружественной, доступной для широкого круга пользователей в исследовательской работе и учебном процессе. Реализация новой версии программы выполнена средствами языка VBA (Visual Basic for Applications) для MS Excel в виде макросов. Тестирование и оценка качества работы программы проводится на статистических источниках по экономической истории России, уже использовавших ранее в работах отечественных исследователей. Апробация показала совпадение полученных результатов с результатами проведенных ранее исследований на данных писцовой книги Воротынского уезда XVII в. Было также проведено сравнение результатов работы новой программы с результатами типологии губерний Европейской части России на рубеже XIX – XX вв. с применением разных алгоритмов нечеткой классификации. Сравнение показало качественно сходные результаты и выявило, что алгоритмы FuzzyClass дают более четкую типологию. Таким образом, созданная программа подтверждает полученные ранее результаты и дает новые возможности историко-типологических исследований.
Ключевые слова:
нечеткая многомерная клссификация, кластер-анализ, теория нечетких множеств, историко-типологические исследования, аграрная типология, алгоритм, компьютерная программа, блок-схема, экономическая история, статистические источники
Abstract: The current study develops a new version of the multidimensional fuzzy classification program for Windows on the basis of FuzzyClass algorithm created by the Department of Historical Information Science of Moscow State University. The previous version of the program (FuzzyClass1) was created over 30 years ago and is still widely used in historical and typological studies because fuzzy classification methods are not yet available in most standard statistical packages. The need for a new version of the program is caused by the fact that FuzzyClass1 was a DOS program and can hardly be adjusted to Windows, Mac, etc. Moreover, there is a need to make it more simple, friendly, accessible to a wide range of students and researchers. The new program was created by means of the VBA (VisualBasicforApplications) for MS Excel. The program is tested and evaluated on the basis of Russian economic history statistical sources earlier addressed to by Russian scholars. The adjustment has demonstrated similar results to previous studies which considered cadastres (pistsovye knigi) of Vorotynskiy Uezd in the 17th century. The authors have also compared the results of the new program with the results gained when typology of the European Russia guberniyas at the turn of the 19th and 20th centuries was carried out with the use of fuzzy classification algorithms. The comparison has demonstrated qualitatively similar results and more precise typology through FuzzyClass algorithms. Thus, the program created confirms previous results and provides new opportunities for typological research in history.
Keywords: fuzzy multidimentional classification, cluster analysis, fuzzy set theory, historical typological research, agrarian tipology, algorith, computer program, flowchart, economic history, statistical sources
Введение
Программа многомерной нечеткой классификации FuzzyClass1 [1, 2]. представляет собой нетипичный пример программного продукта, созданного для историко-типологических исследований более 30 лет назад и остающегося востребованным, в то время как перестали использоваться почти все авторские программы, разработанные в 1980–2000-х гг. Очевидно, авторские программные продукты, как универсальные, так и специализированные, не имеют тех преимуществ, которыми обладает коммерческое программное обеспечение: они часто написаны на устаревших языках программирования, имеют не слишком удобный интерфейс, пользователю непросто их осваивать, отсутствует обязательное для коммерческих программ сопровождение и обновление. Все это предсказывает таким программам короткую жизнь. Кроме того, в настоящее время многие их функции реализованы в современных стандартных статистических пакетах, таких, например, как Statistica.
Но, с другой стороны, в профессиональной среде существуют специализированные программы, которые пользуются спросом в течение долгого времени, что связано с реализацией в этих программах методов анализа (в данном случае – методов нечеткой классификации), которые (пока) отсутствуют в большинстве стандартных пакетов. Появляются и новые интегрированные пакеты прикладных программ, такие, как R, которые уже включают такие методы. Однако пока для проведения нечеткой классификации в этом пакете требуется освоение языка R и работа с интерфейсом командной строки, что создает для гуманитария существенные проблемы.
Программа FuzzyClass1 не ставит перед пользователем проблем освоения языков программирования. Тем не менее, она была создана в операционной системе DOS, не использует графический интерфейс, что затрудняет ее адаптацию для операционных систем Windows, Mac и др. Поэтому авторами была поставлена задача разработки новой, кроссплатформенной версии программы. Актуальность этой задачи связана также с необходимостью сделать программу более простой, дружественной, доступной для широкого круга пользователей.
Применение методов многомерного статистического анализа в исторических исследованиях началось в 1970-х гг., в эпоху квантитативной истории, но особый интерес к ним возник вместе с новыми возможностями компьютерной обработки массовых источников, которые дали исследователям персональные компьютеры. Методологические и методические вопросы применения многомерного статистического анализа в исторических исследованиях подробно рассмотрены в монографии Л.И. Бородкина [3]. Среди всех методов многомерного анализа наибольшей популярностью пользовался (и до сих пор пользуется) кластерный анализ и другие методы классификации, которые применяются в историко-типологических исследованиях.
Методы кластерного анализа были представлены в составе универсальных статистических пакетов (например, SPSS) сначала для «больших ЭВМ», а затем и для персональных компьютеров. В нашей стране кластерный анализ впервые был использован историками в конце 1970-х гг. в исследованиях по экономической истории в лаборатории исторической информатики на кафедре источниковедения МГУ (глава по многомерному статистическому анализу уже в 1984 году вошла в учебник «Количественные методы в исторических исследованиях», созданный на кафедре [4, с. 268–276]).
Наиболее известными примерами историко-типологического исследования являются работы И.Д. Ковальченко и Л.И. Бородкина, посвященные аграрной и промышленной типологии губерний Европейской России по данным статистических источников [5, 6]. Для построения аграрной типологии губерний Европейской России на рубеже XIX – XX вв. на основе традиционного кластерного анализа авторами были отобраны 19 показателей, характеризующих земельные отношения, состояние сельскохозяйственного производства, глубину и особенности буржуазной аграрной эволюции.
В результате анализа было выделено 15 «мини-кластеров», которые еще не были типами в содержательном смысле. Затем эти кластеры, включавшие сходные по аграрному облику губернии, были объединены в несколько макротипов аграрного развития губерний Европейской России. Так как группы губерний, составляющие эти типы, включают территориально-смежные губернии, то, характеризуя эти типы, И.Д. Ковальченко и Л.И. Бородкин использовали терминологию, которая отражает природно-географические свойства типов.
Один, территориально наиболее обширный тип представляют 19 губерний нечерноземной полосы, от западных до приуральских включительно. Эта совокупность губерний была названа нечерноземным типом аграрного развития. Второй тип образовали 16 средне-южно-черноземных губерний. Этот тип охватывал обширную территорию Черноземной зоны, простирающуюся от Средней Волги до Бессарабии и Подолии, и был назван среднечерноземным типом аграрного развития. Третий макротип, названный южностепным, включал 6 южных и юго-восточных степных губерний, охвативших территорию от Бессарабии до Казахстана. Четвертый, прибалтийский, тип аграрного развития был представлен тремя прибалтийскими и Ковенской губерниями. Наконец, пятый тип, в который входили Петербургская и Московская губернии, получил название столичного.
Была также выделена группа губерний (Астраханская, Олонецкая и Архангельская), которые остались «в стороне» от основных классификационных групп. В силу окраинного положения и несущественного влияния на сельскохозяйственное производство эти губернии не оказывали заметного воздействия на общую картину аграрного строя Европейской России [3, с. 71–73]. Однако Архангельскую и Олонецкую губернии можно выделить в шестой, северный, тип.
Таким образом, объединение «мини-кластеров» в «макро-кластеры» позволило построить типологию, т.е. выделить несколько типов аграрного развития губерний Европейской России. Подсчет коэффициентов вариации 19 признаков по каждому кластеру показал их однородность, т. к. в среднем эти коэффициенты во всех пяти типах не превышали 35%.
Хотя кластер-анализ относится к методам многомерной статистики, относительная простота его использования и интерпретации результатов привели к тому, что он стал весьма популярным в квантитативных историко-типологических исследованиях, наряду с дескриптивной статистикой, корреляционным анализом и анализом динамики [7, с. 51–52]. Во многих работах, которые сегодня публикуются в изданиях Ассоциации «История и компьютер», кластер-анализ по-прежнему является одним из востребованных инструментов исследования [8, 9, 10, 11].
Безусловно, кластер-анализ доказал свою эффективность в исторических исследованиях. Однако этот метод, как и многие другие методы автоматической классификации, основан на принципе однозначного отнесения каждого объекта совокупности к одному и только одному классу. Это, очевидно, не может в полной мере соответствовать сложной исторической реальности, в которой каждый объект может проявлять свойства не одного, а нескольких классов и, следовательно, может быть отнесен более чем к одному классу. Кроме того, концепция стандартного кластер-анализа не дает возможности анализировать не только «переходные», но и «изолированные» объекты, а также остается неясной «природа» ядра и периферии класса [1, с. 89]. Эти проблемы решает теория нечетких множеств.
В 1970-х гг. в значительной мере в ответ на запросы социально-гуманитарных наук математика предложила новые методы классификации, основанные на т. н. теории нечетких множеств (FuzzySetTheory). О теории нечетких множеств и ее применении в исторических исследованиях см. [3, 2]. В соответствии со спецификой задач классификации в гуманитарных приложениях, где, как правило, отсутствуют четкие границы между классами, подобный подход позволил ввести в процесс классификации объектов понятия степени принадлежности к множеству, как количественной оценки степени типичности объектов каждого класса.
Публикации о возможностях использования историками теории нечетких множеств появились в начале 1980-х гг. [12, 13, 14] В настоящее время существует немало алгоритмов и компьютерных программ, основанных на этой теории, и уже накоплен опыт их применения в исторических исследованиях.
Первые исторические исследования с использованием методов нечеткой классификации проводилась на статистических источниках по экономической истории России: прежде всего, на уже апробированных данных, использованных для построения аграрной типологии губерний Европейской России на рубеже XIX – XX вв. [15].
Результаты нечеткой классификации в основном подтвердили и скорректировали выводы предыдущей работы. В начале исследования, опираясь на результаты кластерного анализа, были построены шесть нечетких классов, но два из них оказались практически пустыми, а остальные четыре класса представляли те же типы, которые получались методом кластер-анализа: нечерноземный, среднечерноземный, степной и прибалтийский типы [15, с. 16–17]. Что касается столичного типа, то эти две губернии представляли, скорее, мини-тип и при выделении макротипов они, фактически с одинаковым весом принадлежности, вошли в нечерноземный тип) [15, с. 17]. Интересно, что те же три губернии, что и при кластерном анализе, а именно, Архангельская, Олонецкая и Астраханская, не вошли ни в один из четырех классов.
Таким образом, построение типологии на тех же данных с помощью методов нечеткой классификации позволило подтвердить и скорректировать выводы предыдущей работы. В дальнейшем на том же источниковом материале и с использованием теории нечетких множеств апробировались методы распознавания образов (дискриминантного анализа), в которых применялись алгоритмы «машинного обучения» – распознавание «с учителем» [16, 17, 18, 13, с. 98–99].
Еще одна апробация методов нечеткой классификации была проведена на данных о феодальном землевладении и хозяйстве в России в первой половине XVII в. по материалам писцовых книг для классификации вотчин и поместий Воротынского уезда [1, 19].
Вотчина и поместье представляли собой не только юридически две различные формы феодального землевладения, но и экономически различные типы хозяйства. Результаты, подтверждающие эту гипотезу, отражены в коллективной монографии Л.В. Милова, М.Б. Булгакова и И.М. Гарсковой [20]. Использование концепции нечетких множеств позволило ввести в процесс классификации объектов понятия степени принадлежности к множеству, как количественной оценки степени типичности объектов каждого класса. Для решения этой задачи необходимы две составляющие: уже имеющаяся классификация и исходные статистические данные по объектам, которые требуется классифицировать. Если полученная с помощью алгоритма классификация совпадает с имеющейся традиционной, то можно сказать, что традиционная нашла дополнительное подтверждение, а также о том, что этот алгоритм работает корректно.
В писцовых книгах указывался юридический статус владения (поместье или вотчина). В проведенном исследовании этот статус как априорная классификация использовался для проверки корректности работы алгоритма и проверки гипотезы о том, что владения, различающиеся своим юридическим статусом, различались по своим экономическим показателям.
Результаты нечеткой классификации объектов на два класса по экономическим показателям подтвердили наличие «поместного» и «вотчинного» типов хозяйств, что свидетельствовало об эффективности метода.
Нечеткая классификация сравнивалась с классификацией, полученной методом кластер-анализа. Во многом результаты обоих методов совпадают: 67% объектов относятся к одному и тому же классу в обоих случаях, в 14% случаев объекты попадают в разные классы. Кроме того, при нечеткой классификации 9 объектов остаются вне классов, но кластер-анализ «принудительно» относит их к определенным классам. В результате нарушается «типологическая чистота»: если в результате нечеткой классификации каждый класс на 2/3 состоял либо из поместий, либо из вотчин, то в результате кластерного анализа классы являются менее однородными: на долю поместий в первом классе 60%, на долю вотчин во втором классе – 62% [1, с. 100]. Таким образом, нечеткая классификация дала более адекватные результаты.
Метод нечеткой классификации получил достаточно широкое распространение в публикациях АИК: в исследованиях по экономической и социальной истории, исторической демографии [21, 22, 23, 24], в археологических исследованиях [25, 26, 27, 28, 29, 30] и даже в анализе текстовых источников: от нормативных актов советского периода [31] до древнерусских текстов [32, 33].
Этот подход предлагает историку гибкий аппарат, максимально учитывающий неоднозначность, неоднородность информации источника. В 1999 г. описание методов нечеткой классификации, наряду с методами традиционного кластер-анализа было включено в учебное пособие по статистике для историков, созданное в лаборатории исторической информатики МГУ [34, с. 113–117].
Создание и тестирование программы FuzzyClass2
Алгоритмы и программы нечеткой классификации базируются на теории нечетких множеств (ТНМ). Нечеткое множество – это класс, в котором нет резкой границы между теми объектами, которые входят и теми, что не входят в него. Каждому объекту присваивается степень принадлежности, величина, принимающая значения от 0 до 1. Чем это значение больше, тем выше степень принадлежности. Если степень принадлежности равна нулю, объект не принадлежит этому множеству. Сумма степеней принадлежности объекта ко всем классам должна быть равна 1. Если степени принадлежности принимают только значения 1 и 0, мы имеем дело с «обычным», «четким» множеством [1, с. 89].
Математически это можно выразить следующим образом:

У каждого нечеткого множества есть ядро, или центр (a), которое определяет некий набор объектов (его еще называют «множеством a-уровня»). Для каждого из них степень принадлежности к данному нечеткому множеству должна быть больше заданного заранее порога, например, 0,9 или 0,8. Математически это выражается следующим образом:
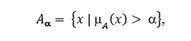
т. е. ядром (a) нечеткого множества А является множество элементов из массива объектов, степень принадлежности которых больше или равна a. Чем ближе a к 1, тем «у́же» состав ядра [1, с. 91]. Иначе говоря, ядро – это группа объектов, определяющих качественное отличие данного типа от всех иных. Чем ближе объект к центру класса, тем ближе к единице степень его принадлежности к нему.
Для того, чтобы распределить объекты по классам, надо перебрать различные комбинации и подсчитать функционал, значение которого требуется минимизировать:

При этом каждая степень принадлежности должна находиться в пределах от нуля до единицы, а сумма степеней принадлежности всем классам для каждого объекта должна равняться единице [1, с. 91–92].
Построить кластеры, или группы со схожими характеристиками позволяет компьютерная программа, реализующая алгоритм нечеткой классификации. Задача такого алгоритма – на основании заданного числа классов «наполнить» их объектами со схожими параметрами, «близкими» друг к другу, при этом отражая «размытость» границ классов реального мира, его неоднозначность.
Для работы программы необходимо задать количество классов, признаков, объектов и значение параметра нечеткости. На выходе программа выдает таблицу степеней принадлежности, средневзвешенных значений признаков по классам, внутриклассовых вариаций и значение функционала.
Параметр нечеткости регулирует «контрастность» типологии. Чем выше его значение, тем более «рыхлым» будет разбиение на классы. Центры классов отражают координаты ядра класса в n-мерном пространстве признаков. Объекты с высокой степенью принадлежности к классу будут иметь значения параметров, наиболее близкие к центру класса. Значения внутриклассовых вариаций отражают степень однородности группы.
В настоящее время существуют немало алгоритмов и компьютерных программ, основанных на теории нечетких множеств. Многие из них основаны на различных версиях известного алгоритма ISODATA (Iterative Self-Organizing Data Analysis Technique). Так, в исследовании И.Д. Ковальченко и Л.И. Бородкина классификация проводилась с помощью модифицированного (Л.И. Бородкиным) алгоритма ISODATA; в работе Л.И. Бородкина и И.М. Гарсковой [1] был использован несколько иной алгоритм классификации, FuzzyClass, для сравнения полученных на его основе результатов с уже имеющейся классификацией. Этот алгоритм был реализован в программе FuzzyClass1, разработанной в 1990-х гг. в лаборатории исторической информатики МГУ (сейчас – кафедра исторической информатики) на языке программирования FORTRAN. Новая версия этой программы, FuzzyClass2, представлена в данной работе.
Программа разработана В.А. Зуевой в ходе выполнения дипломного проекта «Типология губерний Европейской России по данным о структуре землевладения в начале XX в. (разработка и использование программы многомерной нечеткой классификации)» (М., 2017; науч. рук. – И.М. Гарскова) на кафедре исторической информатики МГУ.
Программа является кроссплатформенной, то есть работает на нескольких видах ОС (Windows OS, Mac OS). Единственное требование к системе – наличие установленного программного пакета Microsoft Office с поддержкой макросов. Алгоритм реализован инструментами языка VBA (Visual Basic for Applications) для MS Excel. Архитектура программы использует модульный подход и включает следующие модули: Interface, Settings, Maths, Data Handling, Main, EfficiencyBoost. Подробное описание алгоритма, блок-схемы и модулей программы дано в приложении.
После установки программы на компьютер пользователя процесс работы выглядит следующим образом:
· Запуск Excel.
· В пустой книге на вкладке «FUZZY» главного меню Excel пользователь запускает выбирает макрос «PreliminaryChanges()».
· Происходит вызов функций из процедуры PreliminaryChanges() и настройка книги.
· Ввод данных для настроек на листе «Settings».
· Ввод данных для анализа на листе «Input».
· В настроенной книге с данными на листе «Input» на вкладке «FUZZY» пользователь выбирает макрос «Algorithm».
· Программа, используя алгоритм многомерной нечеткой классификации, подбирает наиболее оптимальное решение для классификации заданных объектов с минимальным значением функционала.
· Результат выводится в виде таблицы и гистограммы на листе «Output» в текущей книге.
Тестирование программы. Так как имеется математическое описание алгоритма, можно проверить корректность работы программы, параллельно проводя вычисления с использованием формул на листе электронной книги на небольших множествах с минимальным набором признаков. В процессе разработки программы использовался рабочий тестовый массив данных (табл. 1). Первый столбец – номера объектов, второй и третий – значения параметров 1 и 2 для каждого из 10-ти объектов. Жирным шрифтом и светло-серым фоном выделены пограничные объекты.
Видно, что данный массив можно разделить на два класса: в одном параметры принимают значения 0 или 1, во втором – 8 и 9; существуют также два пограничных объекта со значениями признаков 6 и 4. Таким образом, в результате мы должны получить довольно четкую картину для 1–4 и 7–10 объектов с весами принадлежности к своему классу, близкими к единице. Для объектов 5 и 6 веса принадлежности должны быть близки к 0,5, т. е. принадлежности этих объектов к обоим классам приблизительно равны.
Таблица 1. Входные данные на 10 объектов. Тестовый массив
|
№
|
Параметр 1
|
Параметр 2
|
|
1
|
0
|
0
|
|
2
|
0
|
1
|
|
3
|
1
|
0
|
|
4
|
1
|
1
|
|
5
|
4
|
6
|
|
6
|
6
|
4
|
|
7
|
10
|
10
|
|
8
|
10
|
9
|
|
9
|
9
|
10
|
|
10
|
9
|
9
|
Программа выдала предсказуемые результаты, веса принадлежности представлены в следующей таблице.
Таблица 2. Веса принадлежности тестового массива
|
|
Class#1
|
Class#2
|
|
|
1
|
0,9997
|
0,0003
|
1
|
|
2
|
0,9999
|
0,0001
|
1
|
|
3
|
0,9999
|
0,0001
|
1
|
|
4
|
1,0000
|
0,0000
|
1
|
|
5
|
0,5017
|
0,4983
|
1
|
|
6
|
0,4983
|
0,5017
|
2
|
|
7
|
0,0003
|
0,9997
|
2
|
|
8
|
0,0001
|
0,9999
|
2
|
|
9
|
0,0001
|
0,9999
|
2
|
|
10
|
0,0000
|
1,0000
|
2
|
В результате работы программы объекты 5 и 6 были классифицированы как пограничные, относящиеся в равной мере к первому и второму классам, что хорошо видно на следующей гистограмме (рис. 1).
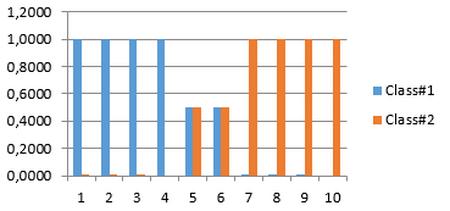
Рис. 1. Веса принадлежности объектов к двум классам
Для отладки работы макросов в книге Excel параллельно проводились вычисления при помощи формул из предыдущей версии программы. Таким же образом программа была протестирована на нескольких пробных массивах данных, подобных описанному выше.
После первичной отладки программы на тестовых массивах, состоящих из небольшого количества объектов, была произведена классификация данных писцовой книги Воротынского уезда, выполненная ранее в работе Л.И. Бородкина и И.М. Гарсковой [1]. Поместья и вотчины Воротынского уезда (49 объектов) были разделены на два класса.
Результаты работы алгоритма с данными писцовой книги представлены в табл. 3. Данные были разбиты на два класса (как и в исходном исследовании) с параметром классификации равным 2 (что снижает контрастность деления объектов на классы). Для порога принадлежности 0,65 в первый и второй классы попали 15 и 25 объектов, соответственно; 9 «пограничных» объектов нельзя отнести однозначно к одному классу. Эти результаты практически полностью совпадают с результатами работы предыдущей версии программы [1, с. 99–100], что доказывает корректность работы алгоритма (небольшие расхождения в значениях весов принадлежности в табл. 3, связаны с различной точностью вычислений в двух версиях программы).
Если изменить параметр нечеткости и выбрать значение 1,5, результаты становятся более контрастными: объекты, попавшие в первый или второй класс, получают более высокие веса принадлежности к «своим» классам, шесть из девяти бывших «пограничных» объектов попадают либо в первый, либо во второй класс, и только три остаются «пограничными».
Таблица 3. Сравнение результатов классификации в первой и второй версиях программыFuzzyClass
|
Объекты
|
1-я версия программы
|
2-я версия программы
|
Объекты
|
1-я версия программы
|
2-я версия программы
|
|
К1
|
К2
|
К1
|
К2
|
К1
|
К2
|
К1
|
К2
|
|
1 сп
|
0,24
|
0,76
|
0,26
|
0,74
|
24 кв
|
0,93
|
0,07
|
0,90
|
0,10
|
|
2 кп
|
0,01
|
0,99
|
0,01
|
0,99
|
25 кв
|
0,98
|
0,02
|
0,99
|
0,01
|
|
3 кп
|
0,42
|
0,58
|
0,45
|
0,55
|
26 мв
|
0,05
|
0,95
|
0,05
|
0,95
|
|
4 кп
|
0,36
|
0,64
|
0,36
|
0,64
|
27 мв
|
0,11
|
0,89
|
0,13
|
0,87
|
|
5 кп
|
0,70
|
0,3
|
0,68
|
0,32
|
28 мв
|
0,2
|
0,8
|
0,22
|
0,78
|
|
6 сп
|
0,37
|
0,63
|
0,41
|
0,59
|
29 св
|
0,6
|
0,4
|
0,61
|
0,39
|
|
7 кп
|
0,98
|
0,02
|
0,97
|
0,03
|
30 св
|
0,25
|
0,75
|
0,27
|
0,73
|
|
8 сп
|
0,96
|
0,04
|
0,97
|
0,03
|
31 св
|
0,12
|
0,88
|
0,14
|
0,86
|
|
9 кп
|
0,18
|
0,82
|
0,19
|
0,81
|
32 кв
|
0,94
|
0,06
|
0,93
|
0,07
|
|
10 сп
|
0,58
|
0,42
|
0,57
|
0,43
|
33 св
|
0,2
|
0,8
|
0,20
|
0,80
|
|
11 кп
|
0,73
|
0,27
|
0,72
|
0,28
|
34 кв
|
0,11
|
0,89
|
0,12
|
0,88
|
|
12 кп
|
0,01
|
0,99
|
0,01
|
0,99
|
35 кв
|
0,08
|
0,92
|
0,09
|
0,91
|
|
13 кп
|
0,71
|
0,29
|
0,70
|
0,30
|
36 кв
|
0,33
|
0,67
|
0,33
|
0,67
|
|
14 мп
|
0,3
|
0,7
|
0,30
|
0,70
|
37 мв
|
0,14
|
0,86
|
0,14
|
0,86
|
|
15 кп
|
0,27
|
0,73
|
0,27
|
0,73
|
38 св
|
0,04
|
0,96
|
0,05
|
0,95
|
|
16 кп
|
0,79
|
0,21
|
0,78
|
0,22
|
39 мв
|
0,44
|
0,56
|
0,48
|
0,52
|
|
17 кп
|
0,65
|
0,35
|
0,70
|
0,30
|
40 кв
|
0,05
|
0,95
|
0,04
|
0,96
|
|
18 кп
|
0,26
|
0,74
|
0,30
|
0,70
|
41 кв
|
0,57
|
0,43
|
0,56
|
0,44
|
|
19 кп
|
0,79
|
0,21
|
0,82
|
0,18
|
42 кв
|
0,1
|
0,9
|
0,12
|
0,88
|
|
20 сп
|
0,87
|
0,13
|
0,91
|
0,09
|
43 мв
|
0,15
|
0,85
|
0,16
|
0,84
|
|
21 сп
|
0,05
|
0,95
|
0,06
|
0,94
|
44 кв
|
0,1
|
0,9
|
0,11
|
0,89
|
|
22 мп
|
0,42
|
0,58
|
0,42
|
0,58
|
45 св
|
0,08
|
0,92
|
0,08
|
0,92
|
|
23 кп
|
0,79
|
0,21
|
0,82
|
0,18
|
46 св
|
0,82
|
0,18
|
0,86
|
0,14
|
|
|
|
|
|
|
47 св
|
0,89
|
0,11
|
0,91
|
0,09
|
|
|
|
|
|
|
48 мв
|
0,31
|
0,69
|
0,33
|
0,67
|
|
|
|
|
|
|
49 св
|
0,53
|
0,47
|
0,53
|
0,47
|
Обозначения: к – крупное(ая), с – среднее(яя), м – мелкое (ая), п – поместье, в – вотчина. Результаты работы программы FuzzyClass1 взяты из указанной статьи Л.И. Бородкина и И.М. Гарсковой. Желтым цветом выделены значения весов принадлежности, превышающие пороговое, серым – оба значения, если они не превышают порогового, т.е. объект является пограничным. (Данные, полученные с помощью программы FuzzyClass2, не выделены цветом для удобства чтения.)
Использование программ FuzzyClass1 и FuzzyClass2 в историко-типологическом исследовании
Для оценки того, какое влияние на результаты классификации оказывает выбор того или иного алгоритма, сравним веса принадлежности объектов классам, полученные в исследовании И.Д. Ковальченко и Л.И. Бородкина с помощью модифицированного алгоритма ISODATA [15, с. 13–14], и веса принадлежности, полученные в данном исследовании с помощью программы FuzzyClass1. Эти результаты существенно различаются. Так, легко убедиться, что в табл. 2 цитируемой статьи практически нет больших значений, превышающих 0,9 или 0,8, за редкими исключениями. Причиной этого является то, что в классическом алгоритме ISODATA значения весов принадлежности для объектов, удаленных от «ядер» классов, плохо поддаются интерпретации. Поэтому целью модификации алгоритма в исследовании И.Д. Ковальченко и Л.И. Бородкина вводится дополнительный, «фиктивный» класс, степень принадлежности к которому характеризует «нетипичность» объекта.
Если провести классификацию того же массива данных с помощью программы FuzzyClass1, получатся результаты, представленные в табл. 4. В этой таблице уровень значений весов принадлежности (при одинаковом параметре нечеткости) выше, а классы являются более «компактными». Тем не менее, состав классов, их ядра и периферия остаются теми же самыми при смене алгоритма. Это свидетельствует о том, что выделенные группы объектов-губерний реально существуют и оба алгоритма их правильно находят. Аналогичные результаты дает новая программа FuzzyClass2 (табл. 5).
Таблица 4. Результаты нечеткой многомерной классификации данных И.Д. Ковальченко и Л.И. Бородкина с помощью программы FuzzyClass1
|
|
I
|
II
|
VI
|
V
|
IV
|
III
|
|
архангельская
|
0,52
|
0,06
|
0,06
|
0,20
|
0,13
|
0,03
|
|
астраханская
|
0,35
|
0,08
|
0,05
|
0,27
|
0,20
|
0,04
|
|
бессарабская
|
0,03
|
0,75
|
0,01
|
0,07
|
0,10
|
0,05
|
|
виленская
|
0,19
|
0,11
|
0,01
|
0,39
|
0,29
|
0,01
|
|
витебская
|
0,33
|
0,04
|
0,01
|
0,22
|
0,40
|
0,01
|
|
владимирская
|
0,08
|
0,03
|
0,00
|
0,85
|
0,03
|
0,00
|
|
вологодская
|
0,82
|
0,01
|
0,00
|
0,11
|
0,05
|
0,00
|
|
волынская
|
0,05
|
0,66
|
0,02
|
0,12
|
0,13
|
0,02
|
|
воронежская
|
0,01
|
0,92
|
0,00
|
0,02
|
0,04
|
0,01
|
|
вятская
|
0,09
|
0,36
|
0,02
|
0,23
|
0,23
|
0,07
|
|
гродненская
|
0,17
|
0,13
|
0,02
|
0,50
|
0,16
|
0,02
|
|
донская
|
0,04
|
0,07
|
0,03
|
0,05
|
0,07
|
0,75
|
|
екатеринославская
|
0,01
|
0,02
|
0,00
|
0,01
|
0,01
|
0,95
|
|
казанская
|
0,06
|
0,45
|
0,00
|
0,34
|
0,13
|
0,01
|
|
калужская
|
0,16
|
0,08
|
0,00
|
0,52
|
0,23
|
0,01
|
|
киевская
|
0,07
|
0,60
|
0,01
|
0,17
|
0,13
|
0,02
|
|
ковенская
|
0,18
|
0,09
|
0,24
|
0,15
|
0,32
|
0,03
|
|
костромская
|
0,07
|
0,01
|
0,00
|
0,89
|
0,03
|
0,00
|
|
курляндская
|
0,01
|
0,01
|
0,97
|
0,01
|
0,01
|
0,01
|
|
курская
|
0,01
|
0,86
|
0,01
|
0,03
|
0,06
|
0,04
|
|
лифляндская
|
0,00
|
0,00
|
0,99
|
0,00
|
0,00
|
0,00
|
|
минская
|
0,23
|
0,08
|
0,02
|
0,21
|
0,45
|
0,02
|
|
могилевская
|
0,08
|
0,17
|
0,02
|
0,08
|
0,62
|
0,03
|
|
московская
|
0,30
|
0,13
|
0,02
|
0,37
|
0,14
|
0,03
|
|
нижегородская
|
0,05
|
0,12
|
0,00
|
0,77
|
0,07
|
0,00
|
|
новгородская
|
0,94
|
0,00
|
0,00
|
0,03
|
0,02
|
0,00
|
|
олонецкая
|
0,34
|
0,11
|
0,07
|
0,24
|
0,16
|
0,07
|
|
оренбургская
|
0,14
|
0,13
|
0,06
|
0,12
|
0,31
|
0,24
|
|
орловская
|
0,00
|
0,98
|
0,00
|
0,01
|
0,01
|
0,00
|
|
пензенская
|
0,00
|
0,95
|
0,00
|
0,02
|
0,03
|
0,00
|
|
пермская
|
0,16
|
0,11
|
0,01
|
0,34
|
0,35
|
0,02
|
|
петербургская
|
0,49
|
0,07
|
0,03
|
0,27
|
0,13
|
0,02
|
|
подольская
|
0,04
|
0,05
|
0,01
|
0,04
|
0,85
|
0,01
|
|
полтавская
|
0,05
|
0,66
|
0,01
|
0,16
|
0,10
|
0,02
|
|
псковская
|
0,86
|
0,01
|
0,00
|
0,06
|
0,07
|
0,00
|
|
рязанская
|
0,01
|
0,93
|
0,00
|
0,04
|
0,02
|
0,00
|
|
самарская
|
0,06
|
0,17
|
0,02
|
0,08
|
0,24
|
0,42
|
|
саратовская
|
0,03
|
0,54
|
0,01
|
0,07
|
0,22
|
0,14
|
|
симбирская
|
0,03
|
0,73
|
0,00
|
0,13
|
0,10
|
0,01
|
|
смоленская
|
0,19
|
0,06
|
0,01
|
0,08
|
0,62
|
0,03
|
|
таврическая
|
0,01
|
0,02
|
0,01
|
0,01
|
0,01
|
0,95
|
|
тамбовская
|
0,00
|
0,95
|
0,00
|
0,01
|
0,02
|
0,01
|
|
тверская
|
0,48
|
0,02
|
0,00
|
0,44
|
0,07
|
0,00
|
|
тульская
|
0,01
|
0,93
|
0,00
|
0,02
|
0,03
|
0,02
|
|
уфимская
|
0,08
|
0,08
|
0,01
|
0,10
|
0,70
|
0,03
|
|
харьковская
|
0,04
|
0,65
|
0,00
|
0,15
|
0,13
|
0,03
|
|
херсонская
|
0,01
|
0,08
|
0,01
|
0,02
|
0,03
|
0,84
|
|
черниговская
|
0,03
|
0,23
|
0,00
|
0,08
|
0,65
|
0,01
|
|
эстляндская
|
0,10
|
0,10
|
0,51
|
0,10
|
0,12
|
0,08
|
|
ярославская
|
0,14
|
0,04
|
0,00
|
0,76
|
0,05
|
0,01
|
Таблица 5. Результаты нечеткой многомерной классификации, данных И.Д. Ковальченко и Л.И. Бородкина с помощью программы FuzzyClass2
|
|
I
|
II
|
VI
|
V
|
IV
|
III
|
|
архангельская
|
0,49
|
0,07
|
0,06
|
0,22
|
0,13
|
0,04
|
|
астраханская
|
0,35
|
0,08
|
0,05
|
0,27
|
0,20
|
0,04
|
|
бессарабская
|
0,03
|
0,73
|
0,01
|
0,06
|
0,12
|
0,05
|
|
виленская
|
0,20
|
0,10
|
0,01
|
0,35
|
0,32
|
0,01
|
|
витебская
|
0,37
|
0,04
|
0,00
|
0,20
|
0,38
|
0,01
|
|
владимирская
|
0,08
|
0,03
|
0,00
|
0,84
|
0,04
|
0,00
|
|
вологодская
|
0,81
|
0,01
|
0,00
|
0,13
|
0,05
|
0,00
|
|
волынская
|
0,05
|
0,65
|
0,02
|
0,11
|
0,14
|
0,02
|
|
воронежская
|
0,01
|
0,91
|
0,00
|
0,02
|
0,05
|
0,01
|
|
вятская
|
0,09
|
0,36
|
0,02
|
0,22
|
0,25
|
0,07
|
|
гродненская
|
0,18
|
0,13
|
0,02
|
0,47
|
0,18
|
0,02
|
|
донская
|
0,04
|
0,07
|
0,03
|
0,05
|
0,07
|
0,75
|
|
екатеринославская
|
0,01
|
0,03
|
0,00
|
0,01
|
0,01
|
0,94
|
|
казанская
|
0,07
|
0,46
|
0,00
|
0,29
|
0,16
|
0,01
|
|
калужская
|
0,16
|
0,08
|
0,00
|
0,49
|
0,26
|
0,01
|
|
киевская
|
0,07
|
0,60
|
0,01
|
0,16
|
0,14
|
0,02
|
|
ковенская
|
0,18
|
0,09
|
0,23
|
0,15
|
0,32
|
0,03
|
|
костромская
|
0,07
|
0,01
|
0,00
|
0,88
|
0,03
|
0,00
|
|
курляндская
|
0,01
|
0,01
|
0,97
|
0,01
|
0,01
|
0,01
|
|
курская
|
0,01
|
0,85
|
0,01
|
0,03
|
0,06
|
0,04
|
|
лифляндская
|
0,00
|
0,00
|
0,99
|
0,00
|
0,00
|
0,00
|
|
минская
|
0,25
|
0,07
|
0,02
|
0,21
|
0,43
|
0,02
|
|
могилевская
|
0,08
|
0,18
|
0,02
|
0,08
|
0,62
|
0,03
|
|
московская
|
0,28
|
0,13
|
0,02
|
0,38
|
0,15
|
0,03
|
|
нижегородская
|
0,06
|
0,14
|
0,00
|
0,71
|
0,10
|
0,00
|
|
новгородская
|
0,94
|
0,00
|
0,00
|
0,03
|
0,02
|
0,00
|
|
олонецкая
|
0,33
|
0,11
|
0,07
|
0,25
|
0,17
|
0,07
|
|
оренбургская
|
0,15
|
0,13
|
0,06
|
0,12
|
0,29
|
0,24
|
|
орловская
|
0,00
|
0,97
|
0,00
|
0,01
|
0,01
|
0,00
|
|
пензенская
|
0,00
|
0,94
|
0,00
|
0,01
|
0,03
|
0,00
|
|
пермская
|
0,16
|
0,11
|
0,01
|
0,33
|
0,36
|
0,02
|
|
петербургская
|
0,46
|
0,07
|
0,03
|
0,28
|
0,13
|
0,02
|
|
подольская
|
0,06
|
0,06
|
0,01
|
0,05
|
0,82
|
0,01
|
|
полтавская
|
0,05
|
0,66
|
0,01
|
0,15
|
0,11
|
0,02
|
|
псковская
|
0,89
|
0,01
|
0,00
|
0,05
|
0,06
|
0,00
|
|
рязанская
|
0,01
|
0,93
|
0,00
|
0,04
|
0,02
|
0,00
|
|
самарская
|
0,07
|
0,17
|
0,02
|
0,08
|
0,24
|
0,43
|
|
саратовская
|
0,04
|
0,53
|
0,01
|
0,06
|
0,23
|
0,14
|
|
симбирская
|
0,03
|
0,72
|
0,00
|
0,11
|
0,12
|
0,01
|
|
смоленская
|
0,24
|
0,07
|
0,02
|
0,10
|
0,55
|
0,03
|
|
таврическая
|
0,01
|
0,02
|
0,01
|
0,01
|
0,01
|
0,95
|
|
тамбовская
|
0,01
|
0,95
|
0,00
|
0,01
|
0,02
|
0,01
|
|
тверская
|
0,42
|
0,02
|
0,00
|
0,50
|
0,07
|
0,00
|
|
тульская
|
0,01
|
0,92
|
0,00
|
0,02
|
0,03
|
0,02
|
|
уфимская
|
0,10
|
0,09
|
0,01
|
0,11
|
0,67
|
0,03
|
|
харьковская
|
0,05
|
0,64
|
0,00
|
0,14
|
0,14
|
0,03
|
|
херсонская
|
0,01
|
0,08
|
0,01
|
0,02
|
0,04
|
0,84
|
|
черниговская
|
0,03
|
0,20
|
0,00
|
0,06
|
0,70
|
0,01
|
|
эстляндская
|
0,10
|
0,10
|
0,51
|
0,10
|
0,12
|
0,08
|
|
ярославская
|
0,12
|
0,04
|
0,00
|
0,78
|
0,05
|
0,01
|
При использовании модифицированного алгоритма ISODATA только 20 из 50 объектов входят в свой класс со степенью принадлежности к другим классам, не превышающей 0,20; для I, IV и V кластеров верно то, что из 29 входящих в них объектов только два имеют вес принадлежности больше 0,5, т. е. эти группы являются наиболее «рыхлыми» по своей структуре и наиболее схожими между собой. Все это говорит о чрезмерной «размытости» полученной типологии [15, с. 15]. На основании анализа этих результатов был сделан вывод о том, что при разбиении объектов необходимо найти более оптимальное количество классов, т. е. разбиение, в котором степени принадлежности будут выше, а пограничных объектов меньше. Если разбить 50 губерний на 4 кластера [15, с. 15–16], выявляются те же основные типы, которые были получены на этих данных методом кластер-анализа: нечерноземный, среднечерноземный, степной и прибалтийский [15, с. 27–28]. При этом столичный тип входит в более широкий тип нечерноземных земель; Архангельская, Олонецкая и Астраханская губернии не входят ни в один класс.
Аналогичные выводы о наличии четырех основных типов аграрного развития губерний Европейской России на рубеже XIX – XX вв. можно сделать по результатам классификации с помощью алгоритма FuzzyClass, который дает более контрастную картину классификации по сравнению с модифицированным алгоритмом ISODATA
Заключение
Историко-типологические исследования остаются важным направлением применения методов компьютеризованного многомерного статистического анализа. Разработка новой версии программы нечеткой многомерной классификации связана с необходимостью создания программного продукта, работающего с разными операционными системами, которые поддерживают пакет MS Office, простого в освоении и доступного в исследовательской работе и учебном процессе для широкого круга пользователей. Для этого была разработана и апробирована на нескольких массивах данных программа на основе алгоритма FuzzyClass средствами VBA Excel.
Алгоритм реализован в виде макросов. После отладки и первичного тестирования созданная программа была апробирована на данных писцовой книги Воротынского уезда XVII в. Апробация показала совпадение полученных результатов с результатами проведенных ранее на этом же материале исследований с использованием программы FuzzyClass1.
Было проведено также сравнение результатов типологии губерний Европейской части России на рубеже XIX – XX вв. на основе одного и того же массива данных (50 губерний и 19 признаков), но с применением разных алгоритмов нечеткой классификации. Проведенное сравнение показало, что разные алгоритмы дают качественно сходные результаты классификации, что свидетельствует о наличии реальных групп (типов аграрной структуры), существовавших в этот период, однако алгоритмы FuzzyClass дают более четкую типологию.
В результате проведенного исследования был разработан и проверен на историческом материале инструмент для классификации, который может быть применен в других исследованиях. Знакомый графический интерфейс табличного процессора Excel облегчает работу с программой (ввод данных, настройку параметров). Помимо удобного для визуального восприятия способа отображения результатов классификации в виде таблиц, в программу встроена функция окрашивания ячеек в соответствии с принадлежностью к классам, для таблицы весов принадлежности введен дополнительный столбец с номерами классов (можно установить фильтр для удобства просмотра состава классов). Была также реализована функция отображения гистограммы, которая позволяет визуализировать распределение по классам.
Таким образом, данная работа открывает новые возможности для историко-типологических исследований с использованием созданной программы нечеткой многомерной классификации FuzzyClass2. В приложении к статье представлено подробное описание алгоритма и программы.
Приложения
Описание модулей программы
1. Interface. Модуль включает процедуры и функции, которые отвечают за форматирование электронной книги (изменение цвета ячеек, границ и прочее). Включает четыре функции:
a. AddSheets()
b. CustomizeInputSheet()
c. CustomizeSettingsSheet()
d. CustomizeOutputSheet()
2. Settings. В данном модуле вводятся основные глобальные переменные (NumberOfParameters, NumberOfObjects, NumberOfClasses, BlurFactor, ObjectsInClass, ObjectsUnsorted), которые будут использованы в ходе работы программы, настраиваются названия листов, добавляются новые, вносятся первичные настройки. Включает функции:
a. Setter()
b. AutoEnterPreliminaryData()
3. Maths. Модуль, который осуществляют математические подсчеты. Включает функции:
a. CalculateAverages() – вычисление средних значений
b. CalculateStandardDeviations() – вычисление стандартных отклонений
c. Normalize() – нормализация значений признаков
d. AssignInitialMu() и FindNewMuValues() – вычисление весов принадлежности m
e. FindFunctional() – вычисление значения функционала и др.
4. DataHandling. Модуль для работы с листами книги (копирование с листа и запись на лист), подсчет занятых ячеек. Включает одну глобальную переменную, InitialInput, а также процедуры и функции:
a. CountObjects() – подсчет объектов ()
b. CountParameters() – подсчет параметров
c. ReadDataIntoArray() – считывание с листа в массив
d. OutputResults() – запись из массива на лист
5. Main. Это основной модуль, модуль запуска. Включает:
a. PreliminaryChanges() – сначала вызываются первоначальные настройки книги, которые добавляют листы с необходимыми именами, происходит первоначальное форматирование книги
b. IncreasePerformance() – для работы основного макроса настраивается программа повышения производительности
c. Algorithm() – вызываются функции и процедуры, осуществляющие анализ и обработку данных
d. RestoreState() – книга восстанавливается до состояния на момент запуска
6. EfficiencyBoost. Модуль для улучшения производительности. Включает две функции:
a. SetEfficiency()
b. RestoreEfficiency().
Первая функция вызывается в модуле Main в функции Algorithm() до начала математических подсчетов, а вторая вызывается в этой же функции, но уже после всех расчетов.
Описание алгоритма
1. Сначала происходит нормализация значений исходных данных, в результате чего получается массив размером m на n, где m – число объектов, а n – число признаков (переменных).
2. Функция AssignInitialMu() присваивает первоначальные значения степени принадлежности (только 1 или 0). В результате получается массив OldMuValues размером m на k, где m – число объектов, а k – число классов.
3. Функция FindTotalMuForEachClass() находит сумму значений весов принадлежности для каждого класса. В результате получаем массив TotalMuForEachClass размером 1 на k, где k – количество классов.
4. Функция FindSumOfProductsForMuAndData() сначала умножает каждое значение из массива нормализованных значений на значение веса принадлежности для каждого класса. Таким образом, получается массив данных размером m на k*n, где m – число объектов, а k*n – число классов, умноженное на число параметров. Т.е. если число объектов m = 100, а число классов k = 3, при этом число параметров n = 3, тогда получается матрица R размером 100x9, если количество классов изменить на 2, тогда размер матрицы станет 100х6. В программе не используется массив такого размера, вместо этого с помощью трех вложенных циклов процедура вычисляет сумму по каждому столбцу. В результате получаем массив SumOfProductsForMuAndData размером k на n (число классов на число параметров, т.е. для k = 2 и n = 3 матрица будет размером 2х3).
5. Функция FindClassCenters(), используя массивы из п. 3 и 4 вычисляет центры классов, деля каждое значение из массива п. 4 (SumOfProductsForMuAndData) на соответствующее значение п. 3 (TotalMuForEachClass). В результате получаем массив такой же размерности (kнаn).
6. Используя или введенные изначально значения, или нормализованные (зависит от параметра типа String, переданного функции: Normal или Initial), происходит подсчет квадратов расстояний по формуле:
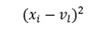
с помощью функции FindDestinationsToCenters(). Таким образом, из каждого значения признака вычитается его значение для центра класса и эта разность возводится в квадрат. В результате получаем двумерный массив DestinationsToClassCenters размером m на k.
7. Далее вызывается функция FindNewMuValues(), в которой происходят две операции:
a. Для каждого значения в массиве DestinationsToClassCenters из п. 6 вычисляется обратное значение в степени 1/(P-1), где P – параметр нечеткости (по умолчанию равен 1,5). На выходе получается массив NewMuValues размером m на k, который на данный момент не содержит еще финальных значений. Параллельно в цикле заполняется массив TotalMuForEachObject размером 1 на m (количество объектов), хранящий сумму по всем признакам квадратов отклонений от центров классов на этом шаге для каждого объекта;
b. каждое значение в массиве NewMuValues делится на соответствующее текущему объекту значение из массива TotalMuForEachObject (т.е. каждое значение делится на сумму этих значений для объекта) и возводится в степень, равную значению P. На выходе имеем готовый массив новых весов принадлежности NewMuValues.
8. Начинает работу цикл с проверкой. На этом этапе каждое значение NewMuValues вычитается из каждого (соответствующего) значения массива OldMuValues, модуль разности возводится в степень P. На каждом шаге цикла получаем временную переменную tempAbsValueInPowerP. Далее происходит две проверки (переменной i, которая отражает количество пройденных циклов, и переменной tempAbsValueInPowerP). В зависимости от результата проверки возможны несколько сценариев:
a. i не превышает 40, и какое-то из tempAbsValueInPowerP превышает 0,01; в этом случае происходит копирование массива NewMuValues в OldMuValues, значение i увеличивается на 1, а цикл возвращается к п. 3;
b. i не превышает 40, и ни одно из tempAbsValueInPowerP не превышает 0,01 (либо i >=40); в этом случае цикл завершается – переход к п. 9.
9. Функция FindFunctional() производит подсчет значения функционала для финальных значений.
10. FindSumOfProductsForMuAndData(“Initial”). Вызывается в последний раз процедура для подсчет сумм произведений исходных значений на значения из массива OldMuValues в степени P (значения в массиве были возведены в степень в процедуре FindNewMuValues() и поэтому на данном шаге уже не нужно проводить возведение в степень).
11. FindTotalMuForEachClass(). Пересчет финальных значений весов принадлежности на основе исходных данных.
12. FindClassCenters(). Пересчет значений центров классов на основе исходных данных.
13. Подсчет значений внутриклассовых вариаций – FindClassVariations(). Сначала происходит подсчет стандартного отклонения по формуле:
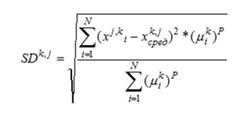
Затем на основе этого значения считают внутриклассовые вариации, отражающие степень однородности класса.
14. Вывод на экран полученных результатов при помощи функции OutputResults(), а также построение диаграммы.
Блок-схема программы
На рис. 2 приводится блок-схема программы. После ввода начальных данных и первичных настроек (количество классов, параметра нечеткости, при желании – выбор цветов для классов), начинает работу главный цикл (MainAlgo()), который последовательно вызывает все процедуры программы и делает проверку из п. 8 приведенного выше описания алгоритма. Далее алгоритм либо завершает цикл, подсчитывая центры классов и внутриклассовые вариации с исходными значениями, либо вновь вызывает все процедуры для нормализованных значений до достижения результата. Если количество шагов превышает 40, цикл завершается с подсчетом конечных результатов, даже если значение valueForCheck превышает 0,01 (в программе переменная называется иначе – tempAbsValueInPowerP, на блок-схеме используется другое название для удобства представления информации).
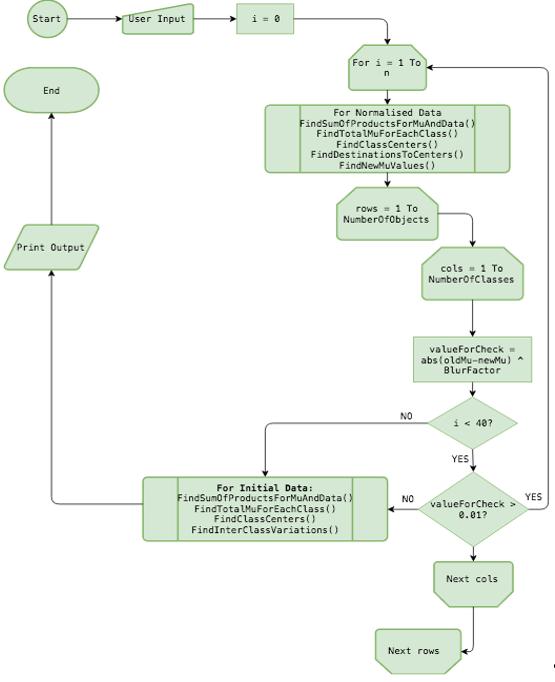
Рис. 2. Блок-схема работы алгоритма
Библиография
1. Бородкин Л.И., Гарскова И.М. Программное обеспечение FUZZYCLASS в историко-типологическом исследовании // История и компьютер: Новые информационные технологии в исторических исследованиях и образовании / Отв. ред. Л.И. Бородкин, В. Леверманн. – St. Katharinen: Scripta Mercaturae Verlag, 1993. – С. 89–103.
2. Бородкин Л.И., Гарскова И.М. FUZZYCLASS: гибкое программное средство построения многомерной типологии объектов социальной природы // Информационный бюллетень Комиссии по применению математических методов и ЭВМ в исторических исследованиях при отделении истории РАН. – 1992. – №7. – С. 51–53.
3. Бородкин Л.И. Многомерный статистический анализ в исторических исследованиях. – М.: МГУ, 1986. – 188 с.
4. Количественные методы в исторических исследованиях / Под ред. И.Д. Ковальченко. – М.: Высшая школа, 1984. – 384 с.
5. Ковальченко И.Д., Бородкин Л.И. Аграрная типология губерний Европейской России на рубеже XIX – XX вв. (опыт многомерного количественного анализа) // История СССР. – 1979. – №1. – С. 59–95.
6. Ковальченко И.Д., Бородкин Л.И. Промышленная типология губерний Европейской России на рубеже XIX – XX вв. (опыт многомерного анализа по данным промышленной переписи 1900 г.) // Математические методы в социально-экономических и археологических исследованиях. – М.: Наука, 1981. – С. 102–128.
7. Гарскова И.М. Историческая информатика и квантитативная история: преемственность и взаимодействие // Анализ и моделирование социально-исторических процессов / Отв. ред. А.В. Коротаев, С.Ю. Малков, Л.Е. Гринин. – М. : КомКнига, 2007. – С. 49–74.
8. Изместьева Т.Ф. Финансово-производственная характеристика предприятий российской промышленности в конце XIX – начале XX вв. Методические аспекты анализа // Круг идей: историческая информатика на пороге XXI века. – М.; Чебоксары : Изд-во «Мосгорархив», 1999. – С. 30–47.
9. Кандаурова Т.Н. Социально-экономические характеристики и модель хозяйственной организации округов военных поселений кавалерии на последнем этапе развития (по материалам массовых статистических источников) // Круг идей: электронные ресурсы исторической информатики. – М.; Барнаул, 2003. – С. 271–288.
10. Ломова С.А. Депозитные, деловые и смешанные банки в России 1874–1913 гг. // Информационный бюллетень Ассоциации «История и компьютер». – 1997. – №21. – С. 64–67.
11. Ульянов О.М. Пространственно-типологическое исследование структуры населения Москвы в конце XIX в. (по материалам переписи населения Москвы 1882 г.) // Информационный бюллетень Ассоциации «История и компьютер». – 2006. – №34. – С. 139–141.
12. Thaller M. The Wings of Change. Problems of a Databank Oriented System Using the Concept of Fuzzy Sets // Papers invented at the 1981 Joint Con-ference of IFDO and IASSIST on the Impact of Computerization on Social Science Research. Universite des Sciences Sociales, Grenoble, France, September 14–18, 1981.
13. Бородкин Л.И. Нечеткие множества, распознавание образов и экономическая история // История, статистика, информатика. – Барнаул, 1995. – С. 98–99.
14. Бородкин Л.И. Об одном подходе к построению размытой классификации объектов социально-экономических систем // Труды II Всесоюзной конференции по системному моделированию социально-экономических процессов. – Таллин, 1983.
15. Ковальченко И.Д., Бородкин Л.И. Вероятностная многомерная классификация в исторических исследованиях. (По данным об аграрной структуре губерний Европейской части России на рубеже XIX – XX вв.) // Математические методы и ЭВМ в исторических исследованиях. – М.: Наука, 1985. – С. 6–30.
16. Бородкин Л.И. Алгоритм распознавания образов с использованием размытых множеств: опыт применения в историко-типологических исследованиях // Информационный бюллетень Ассоциации «История и компьютер». – 2013. – №40. – С. 26–33.
17. Бородкин Л.И. Дискриминантный анализ с использованием концепции нечетких множеств в задаче оценки двух путей аграрной эволюции России на рубеже XIX – XX вв. // Историческая информатика. – 2013. – №3. – С. 30–38.
18. Borodkin L. Fuzzyness in Multivariate Analysis of Historical Data Using a Pattern Recognition Algorithm Based on Fuzzy Set Concepts // Statistics for Historians: Standard Packages and Specific Historical Software. – St. Katharinen: Scripta Mercaturae Verlag, 1995. – P. 95–104.
19. Borodkin L.I., Garskova I.M. FUZZYCLASS: A New Tool for Typological Analysis in Historical Research // History and Computing in Eastern Europe. – St. Katharinen: Scripta Mercaturae Verlag, 1993. – P. 71–83.
20. Милов Л.В., Булгаков М.Б. Гарскова И.М. Тенденции аграрного развития России первой половины XVII столетия: историография, компьютер, методы исследования. – М.: МГУ, 1986. – 303 с.
21. Тихонов А.И., Белова Е.Б. Бельгийские компании в России (1890–1914): анализ характеристик выживаемости // Круг идей: макро-и микро-подходы в исторической информатике. – Минск, 1998. – Т. 2. – С. 34–59.
22. Владимиров В.Н., Колдаков Д.В. Образование населенных пунктов Алтайского края: история во времени и пространстве // История, карта, компьютер. Сборник научных трудов / Отв. ред. В.Н. Владимиров. – Барнаул : Изд-во Алт. ун-та, 1998. – С. 24–44.
23. Пиотух Н.В. Пространственно-хозяйственная типология. Проблема выбора метода классификации // Круг идей: макро-и микроподходы в исторической информатике. Минск, 1998. – Т. 2. – С. 5–19.
24. Якимова И., Владимиров В.Н. Программа FUZZYCLASS: новые возможности исторического исследования (Проблемы типологии сибирской крестьянской общины) // История, статистика, информатика. – Барнаул, 1995. – С. 102–111.
25. Абдулганеев М.Т., Владимиров В.Н. Программа FUZZYCLASS: новые возможности археологического исследования (типология поселений Алтая раннего железного века) // Круг идей: новое в исторической информатике. – М., 1994. – С. 121–128.
26. Абдулганеев М.Т., Владимиров В.Н. Типология поселений Алтая 6–2 вв. до н.э. Барнаул: Изд-во Алт. ун-та, 1997. – 148 с.
27. Беседин В.И. Об эффективности и надежности метода размытой классификации // Информационный бюллетень Ассоциации «История и компьютер». – 1996. – №17. – С. 80–81.
28. Беседин В.И. Применение метода размытой классификации для мор-фологического анализа древней керамики // Информационный бюллетень Ассоциации «История и компьютер». – 1995. – №14. – С. 76–77.
29. Кокорина Ю.Г., Лихтер Ю.А. Опыт использования программы нечеткой классификации FUZZYCLASS для исследования семантики изображений на скифском оружии // Круг идей: междисциплинарные подходы в исторической информатике. – М.: МГУ, 2008. – С. 301–309.
30. Лихтер Ю.А. Классификация древних материалов с использованием программы нечеткой классификации FUZZYCLASS // Информационный бюллетень Ассоциации «История и компьютер». – 2000. – №26/27. – С. 76–82.
31. Гребениченко С.Ф. Статистическая модель путей макрорегулирования промысловой сферы в 1920-е годы (на основе текстовой информации нормативных актов) // Информационный бюллетень Ассоциации «История и компьютер». – 1996. – №17. – С. 120–123.
32. Шпирко С.В. Применение теории нечетких множеств к задаче генеалогической классификации в текстологическом исследовании // Историческая информатика. – 2013. – №3. – С. 39–52.
33. Шпирко С.В., Нестеров А.Ю. Программное приложение Programma’s Edit редактирования текстов, интегрированное в программный комплекс PFuzClass нечеткой генеалогической классификации для текстологических задач // Историческая информатика. – 2017. – №4. – С. 67–77.
34. Компьютеризованный статистический анализ для историков: Учебное пособие / Под ред. Л.И. Бородкина и И.М. Гарсковой. – М.: МГУ, 1999. – 187 с.
References
1. Borodkin L.I., Garskova I.M. Programmnoe obespechenie FUZZYCLASS v istoriko-tipologicheskom issledovanii // Istoriya i komp'yuter: Novye informatsionnye tekhnologii v istoricheskikh issledovaniyakh i obrazovanii / Otv. red. L.I. Borodkin, V. Levermann. – St. Katharinen: Scripta Mercaturae Verlag, 1993. – S. 89–103.
2. Borodkin L.I., Garskova I.M. FUZZYCLASS: gibkoe programmnoe sredstvo postroeniya mnogomernoi tipologii ob''ektov sotsial'noi prirody // Informatsionnyi byulleten' Komissii po primeneniyu matematicheskikh metodov i EVM v istoricheskikh issledovaniyakh pri otdelenii istorii RAN. – 1992. – №7. – S. 51–53.
3. Borodkin L.I. Mnogomernyi statisticheskii analiz v istoricheskikh issledovaniyakh. – M.: MGU, 1986. – 188 s.
4. Kolichestvennye metody v istoricheskikh issledovaniyakh / Pod red. I.D. Koval'chenko. – M.: Vysshaya shkola, 1984. – 384 s.
5. Koval'chenko I.D., Borodkin L.I. Agrarnaya tipologiya gubernii Evropeiskoi Rossii na rubezhe XIX – XX vv. (opyt mnogomernogo kolichestvennogo analiza) // Istoriya SSSR. – 1979. – №1. – S. 59–95.
6. Koval'chenko I.D., Borodkin L.I. Promyshlennaya tipologiya gubernii Evropeiskoi Rossii na rubezhe XIX – XX vv. (opyt mnogomernogo analiza po dannym promyshlennoi perepisi 1900 g.) // Matematicheskie metody v sotsial'no-ekonomicheskikh i arkheologicheskikh issledovaniyakh. – M.: Nauka, 1981. – S. 102–128.
7. Garskova I.M. Istoricheskaya informatika i kvantitativnaya istoriya: preemstvennost' i vzaimodeistvie // Analiz i modelirovanie sotsial'no-istoricheskikh protsessov / Otv. red. A.V. Korotaev, S.Yu. Malkov, L.E. Grinin. – M. : KomKniga, 2007. – S. 49–74.
8. Izmest'eva T.F. Finansovo-proizvodstvennaya kharakteristika predpriyatii rossiiskoi promyshlennosti v kontse XIX – nachale XX vv. Metodicheskie aspekty analiza // Krug idei: istoricheskaya informatika na poroge XXI veka. – M.; Cheboksary : Izd-vo «Mosgorarkhiv», 1999. – S. 30–47.
9. Kandaurova T.N. Sotsial'no-ekonomicheskie kharakteristiki i model' khozyaistvennoi organizatsii okrugov voennykh poselenii kavalerii na poslednem etape razvitiya (po materialam massovykh statisticheskikh istochnikov) // Krug idei: elektronnye resursy istoricheskoi informatiki. – M.; Barnaul, 2003. – S. 271–288.
10. Lomova S.A. Depozitnye, delovye i smeshannye banki v Rossii 1874–1913 gg. // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 1997. – №21. – S. 64–67.
11. Ul'yanov O.M. Prostranstvenno-tipologicheskoe issledovanie struktury naseleniya Moskvy v kontse XIX v. (po materialam perepisi naseleniya Moskvy 1882 g.) // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 2006. – №34. – S. 139–141.
12. Thaller M. The Wings of Change. Problems of a Databank Oriented System Using the Concept of Fuzzy Sets // Papers invented at the 1981 Joint Con-ference of IFDO and IASSIST on the Impact of Computerization on Social Science Research. Universite des Sciences Sociales, Grenoble, France, September 14–18, 1981.
13. Borodkin L.I. Nechetkie mnozhestva, raspoznavanie obrazov i ekonomicheskaya istoriya // Istoriya, statistika, informatika. – Barnaul, 1995. – S. 98–99.
14. Borodkin L.I. Ob odnom podkhode k postroeniyu razmytoi klassifikatsii ob''ektov sotsial'no-ekonomicheskikh sistem // Trudy II Vsesoyuznoi konferentsii po sistemnomu modelirovaniyu sotsial'no-ekonomicheskikh protsessov. – Tallin, 1983.
15. Koval'chenko I.D., Borodkin L.I. Veroyatnostnaya mnogomernaya klassifikatsiya v istoricheskikh issledovaniyakh. (Po dannym ob agrarnoi strukture gubernii Evropeiskoi chasti Rossii na rubezhe XIX – XX vv.) // Matematicheskie metody i EVM v istoricheskikh issledovaniyakh. – M.: Nauka, 1985. – S. 6–30.
16. Borodkin L.I. Algoritm raspoznavaniya obrazov s ispol'zovaniem razmytykh mnozhestv: opyt primeneniya v istoriko-tipologicheskikh issledovaniyakh // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 2013. – №40. – S. 26–33.
17. Borodkin L.I. Diskriminantnyi analiz s ispol'zovaniem kontseptsii nechetkikh mnozhestv v zadache otsenki dvukh putei agrarnoi evolyutsii Rossii na rubezhe XIX – XX vv. // Istoricheskaya informatika. – 2013. – №3. – S. 30–38.
18. Borodkin L. Fuzzyness in Multivariate Analysis of Historical Data Using a Pattern Recognition Algorithm Based on Fuzzy Set Concepts // Statistics for Historians: Standard Packages and Specific Historical Software. – St. Katharinen: Scripta Mercaturae Verlag, 1995. – P. 95–104.
19. Borodkin L.I., Garskova I.M. FUZZYCLASS: A New Tool for Typological Analysis in Historical Research // History and Computing in Eastern Europe. – St. Katharinen: Scripta Mercaturae Verlag, 1993. – P. 71–83.
20. Milov L.V., Bulgakov M.B. Garskova I.M. Tendentsii agrarnogo razvitiya Rossii pervoi poloviny XVII stoletiya: istoriografiya, komp'yuter, metody issledovaniya. – M.: MGU, 1986. – 303 s.
21. Tikhonov A.I., Belova E.B. Bel'giiskie kompanii v Rossii (1890–1914): analiz kharakteristik vyzhivaemosti // Krug idei: makro-i mikro-podkhody v istoricheskoi informatike. – Minsk, 1998. – T. 2. – S. 34–59.
22. Vladimirov V.N., Koldakov D.V. Obrazovanie naselennykh punktov Altaiskogo kraya: istoriya vo vremeni i prostranstve // Istoriya, karta, komp'yuter. Sbornik nauchnykh trudov / Otv. red. V.N. Vladimirov. – Barnaul : Izd-vo Alt. un-ta, 1998. – S. 24–44.
23. Piotukh N.V. Prostranstvenno-khozyaistvennaya tipologiya. Problema vybora metoda klassifikatsii // Krug idei: makro-i mikropodkhody v istoricheskoi informatike. Minsk, 1998. – T. 2. – S. 5–19.
24. Yakimova I., Vladimirov V.N. Programma FUZZYCLASS: novye vozmozhnosti istoricheskogo issledovaniya (Problemy tipologii sibirskoi krest'yanskoi obshchiny) // Istoriya, statistika, informatika. – Barnaul, 1995. – S. 102–111.
25. Abdulganeev M.T., Vladimirov V.N. Programma FUZZYCLASS: novye vozmozhnosti arkheologicheskogo issledovaniya (tipologiya poselenii Altaya rannego zheleznogo veka) // Krug idei: novoe v istoricheskoi informatike. – M., 1994. – S. 121–128.
26. Abdulganeev M.T., Vladimirov V.N. Tipologiya poselenii Altaya 6–2 vv. do n.e. Barnaul: Izd-vo Alt. un-ta, 1997. – 148 s.
27. Besedin V.I. Ob effektivnosti i nadezhnosti metoda razmytoi klassifikatsii // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 1996. – №17. – S. 80–81.
28. Besedin V.I. Primenenie metoda razmytoi klassifikatsii dlya mor-fologicheskogo analiza drevnei keramiki // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 1995. – №14. – S. 76–77.
29. Kokorina Yu.G., Likhter Yu.A. Opyt ispol'zovaniya programmy nechetkoi klassifikatsii FUZZYCLASS dlya issledovaniya semantiki izobrazhenii na skifskom oruzhii // Krug idei: mezhdistsiplinarnye podkhody v istoricheskoi informatike. – M.: MGU, 2008. – S. 301–309.
30. Likhter Yu.A. Klassifikatsiya drevnikh materialov s ispol'zovaniem programmy nechetkoi klassifikatsii FUZZYCLASS // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 2000. – №26/27. – S. 76–82.
31. Grebenichenko S.F. Statisticheskaya model' putei makroregulirovaniya promyslovoi sfery v 1920-e gody (na osnove tekstovoi informatsii normativnykh aktov) // Informatsionnyi byulleten' Assotsiatsii «Istoriya i komp'yuter». – 1996. – №17. – S. 120–123.
32. Shpirko S.V. Primenenie teorii nechetkikh mnozhestv k zadache genealogicheskoi klassifikatsii v tekstologicheskom issledovanii // Istoricheskaya informatika. – 2013. – №3. – S. 39–52.
33. Shpirko S.V., Nesterov A.Yu. Programmnoe prilozhenie Programma’s Edit redaktirovaniya tekstov, integrirovannoe v programmnyi kompleks PFuzClass nechetkoi genealogicheskoi klassifikatsii dlya tekstologicheskikh zadach // Istoricheskaya informatika. – 2017. – №4. – S. 67–77.
34. Komp'yuterizovannyi statisticheskii analiz dlya istorikov: Uchebnoe posobie / Pod red. L.I. Borodkina i I.M. Garskovoi. – M.: MGU, 1999. – 187 s.
|
 Рус
Рус










