|
Кибернетика и программирование
Правильная ссылка на статью:
Файсханов И.Ф.
Аутентификация пользователей при помощи устойчивого клавиатурного почерка со свободной выборкой текста
// Кибернетика и программирование.
2018. № 3.
С. 72-86.
DOI: 10.25136/2644-5522.2018.3.25044 URL: https://nbpublish.com/library_read_article.php?id=25044
Аутентификация пользователей при помощи устойчивого клавиатурного почерка со свободной выборкой текста
Файсханов Ирек Фоатович
преподаватель, кафедра Информационного обеспечения органов внутренних дел, Федеральное государственное казенное образовательное учреждение высшего образования «Уральский юридический институт Министерства внутренних дел Российской Федерации»
620057, Россия, Свердловская область, г. Екатеринбург, ул. Корепина, 66
Fayskhanov Irek Foatovich
Lecturer, Department of Information Support of Internal Affairs Bodies, "Ural Law Institute of the Ministry of Internal Affairs of the Russian Federation"
620057, Russia, Sverdlovskaya oblast', g. Ekaterinburg, ul. Korepina, 66

|
inf-sec-it@yandex.ru
|
|
 |
|
DOI: 10.25136/2644-5522.2018.3.25044
Дата направления статьи в редакцию:
19-12-2017
Дата публикации:
22-06-2018
Аннотация:
Предметом исследования в данной работе является динамический процесс аутентификации пользователей при помощи клавиатурного почерка со свободной выборкой текста. Данный процесс представляет собой регулярную проверку пользователя по принципу "свой-чужой": пользователь, осуществляя ввод текста находится под непрерывным контролем данной системы и, в случае не совпадения идентификационных признаков получает отказ системы в дальнейшей работе. Свободная выборка подразумевается следующим образом: пользователь, осуществляет ввод текста, исходя из своих текущих задач, система в свою очередь, данную работу анализирует, выделяет признаки, обучается, а в случае несоответствия признаков прекращает доступ. Метод исследования применяемый в данной работе – теоретический, состоящий из исследований, поиска и расчетов. Также применяется эмпирический метод, который состоит из эксперимента, сравнения и изучения. Новизна данной работы заключается в следующем. На сегодняшний день наиболее популярным методом аутентификации является пароль. Однако, пароль постепенно вытесняют биометрические средства аутентификации. Например, на сегодняшний день, многие смартфоны оснащены функцией сканирования отпечатка пальца. Тем не менее, несмотря на эффективность данного метода, метод клавиатурной аутентификации имеет свои преимущества: система сканирования отпечатка пальца имеет риск не распознать палец, если он будет поранен, методы взлома данного метода уже существуют и, самое главное, предложенная система клавиатурного почерка осуществляет контроль за вводом непрерывно, что позволит во-первых, не допустить злоумышленника на этапе аутентификации, а также обнаружить его, если он, например, обманным путем смог получить доступ к системе.
Ключевые слова:
информационная безопасность, аутентификация, биометрия, клавиатурный почерк, динамическая аутентификация, распознавание, анализ, нормальное распределение, статистика, эксперименты
Abstract: The subject of the research in this work is a dynamic process of user authentication using keyboard handwriting with free text selection.This process is a regular check of the user on a "friend-to-another" principle: the user entering the text is under continuous monitoring of the system and, in case of non-coincidence of the identification characteristics, the system refuses to continue working.The free sample is understood as follows: the user performs text input based on his current tasks, the system in turn analyzes this work, extracts signs, learns, and in case of inconsistency of characteristics, stops access. The research method used in this work is theoretical, consisting of research, search and calculations. An empirical method is also used, which consists of experiment, comparison, and study. The novelty of this paper is as follows. To date, the most popular authentication method is the password.However, the password gradually displaces the biometric means of authentication. For example, to date, many smartphones are equipped with a fingerprint scanning feature.Nevertheless, despite the effectiveness of this method, the method of keyboard authentication has its advantages: the fingerprint scanning system has the risk of not recognizing the finger, if it is injured, hacking methods of this method already exist and, most importantly, the proposed keyboard handwriting system controls by entering continuously, which will allow first, to prevent an attacker from entering the authentication phase, and also to detect it if, for example, he could, by fraudulent means, gain access to the system.
Keywords: information security, authentication, biometry, keyboard handwriting, dynamic authentication, recognition, analysis, normal distribution, statistics, experiments
Введение
С самых ранних этапов развития человечества человеку было необходимо различать своих от чужих. Применялись различные методы распознавания: с помощью имени, татуировок, определенной одежды, знаков на одежде. Для того, чтобы на поле боя отличить своих солдат от неприятеля, у военных появилась форменная одежда со специальными знаками, с развитием флота, на кораблях начали появляться флаги государств. В XIV веке начали появляться первые удостоверительные документы личности. И на сегодняшний день задача отличать своих от посторонних не перестала быть актуальной, более того, в ходе всеобъемлющей информатизации общества, одной из приоритетных задач, в плане обеспечения информационной безопасности, является вопрос проверки подлинности пользователя, который пытается получить доступ в систему. Данный процесс называется аутентификацией.
Аутентификация с точки зрения информационной безопасности является базовым инструментом, позволяющим предотвратить несанкционированный доступ к информации. Руководящий документ Гостехкомиссии России [1] данное понятие формулирует следующим образом: проверка принадлежности субъекту доступа предъявленного им идентификатора; подтверждение подлинности. Соответственно, задача аутентификации заключается в следующем: субъект предъявляет некоторый идентификатор, позволяющий подтвердить подлинность его личности, система аутентификации выполняет операцию проверки идентификации. В случае положительного результата операции – разрешение доступа, в противном случае – блокировка доступа.
Данный принцип может быть реализован различными способами. Контрольно-пропускной пункт какого-либо учреждения, в котором имеется сотрудник службы безопасности, контролирующий посетителей по удостоверяющим документам, либо установлена система контроля и управления доступом, обеспечивающая доступ по электронным пропускам, которые необходимо приложить к считывающему устройству данной системы. Система аутентификации операционной системы, предоставляющая доступ к системе, после верно введенного пароля. Программная оболочка банкомата, позволяющая получить доступ к управлению лицевым счетом после верно введенного пароля. Подобных примеров много, но общим остается одно: имеется определенный идентификатор, представляющий собой пароль, который необходимо помнить или определенный ключ, пропуск или карта, наличие которых могут позволить получить доступ к тому или иному объекту.
Успешно развивающаяся область информационных технологий на сегодняшний день предлагает огромное разнообразие механизмов аутентификации [2]: по отпечатку пальцев, по распознаванию лица, по распознаванию голоса, по распознаванию радужной оболочки глаза, по геометрии руки, верификации подписи, ДНК, сетчатки глаза, термограммы, походки, формы ушей и многих других. Существует множество работ, подтверждающих успехи в данных областях [3, 4].
Так, С.О. Баранов и Д.Б. Абрамов в своей работе [3] рассматривают технологию аутентификации пользователя по венозному рисунку кистей рук. Авторы рассмотрели продукты, имеющие аналогичный принцип работы, проанализировали проблемные вопросы данной тематики, раскрыли принцип аутентификации на основе данного метода и определили преимущества своего механизма.
Не менее актуальной является работа коллектива авторов Т.И. Лапиной, Д.В. Лапина, Е.А Петрик [4]. В данной работе рассматривается проблематика обработки рукописного текста. Результаты научной деятельности в перспективе авторы предлагают внедрить в системы контроля доступа.
В ходе данной работы будет рассмотрена аутентификация по клавиатурному почерку. В число преимуществ данной технологии можно отнести: отсутствие какого-либо идентификатора, который может быть утерян или украден, отсутствие необходимости в запоминании пароля, а также нет необходимости в дополнительном оборудовании.
Цели работы: проанализировать российские и зарубежные источники по тематике клавиатурного почерка, определить принципы, предлагаемые авторами для реализации механизма аутентификации, сравнить их, выявить недостатки и достоинства, а также рассмотреть на фоне представленных методик собственный принцип клавиатурной аутентификации.
Анализ источников по данной проблеме
В ходе изучения источников по данной тематике, внимание стоит уделить работе А.Н. Савинова [5]. Автор рассматривал текущую проблему аутентификации клавиатурного почерка.
Преимуществами аутентификации посредством клавиатурного почерка по сравнению с парольной защитой, по мнению автора, является невозможность обмана системы путем хищения пароля, его взлома или имитации атрибутов. Также немаловажным фактором, с точки зрения, А.Н. Савинова является тот факт, что подмена законно авторизованного пользователя невозможна.
Принцип, который берет за основу автор – теорию вероятностей и математическую статистику, рассматривает теорию нормального распределения. В качестве характеристики клавиатурного почерка берется за основу математическое ожидание времени удержания клавиш. Данная характеристика рассматривается в виде бимодального распределения, что, по мнению А.Н. Савинова позволяет минимизировать ошибки первого и второго рода в процессе распознавания пользователя, а также позволяет оптимизировать время на создание шаблона клавиатурного почерка и на авторизацию пользователя. Метод распознавания заключается в следующем: рассматривается время ввода «часто употребляемых в языке последовательности (N-грамм)» [5, стр. 4] и производится анализ времени удержания клавиш. Автор отмечает, что реализованная им система имеет точность 99 %.
Автор несколько раз осуществляет измерение времени удержания для каждой клавиши, затем составляет следующую выборку:
X1,X2,…,XN,
где Xi – время удержания клавиши.
Далее вычисляется среднее значение Xср и имеется следующий результат:
μ=Xср+DX,
где μ – результат измерений,
DX – ошибка измерений.
Надежностью данной модели является вероятность P того, что истинное значение находится в данном доверительном интервале выборки.
Не менее интересна работы Ю.А. Брюхомицкого [6]. В его работе «Гистограммный метод распознавания клавиатурного почерка» рассматривается задача по «повышению точности клавиатурных средств аутентификации» [6, стр. 55]. Принцип заключается в следующем: данные, которые подлежат анализу – это особенности динамики работы на клавиатуре пользователя. За эталон клавиатурного почерка пользователя берется сочетание длительностей удержания клавиш (t1, t2,..., tn) и пауз между удержаниями (t12, t23,..., t(n-1)n). Таким образом, в данном случае эталоном будет являться совокупность данных образцов, составляющих обучающую выборку.
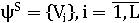 , ,
гдеVj=tj, L – количество образцов клавиатурного почерка пользователя.
В данном случае, задача аутентификации заключается в том, чтобы классифицировать вектора клавиатурного почерка, полученные в ходе процедуры ввода, на классы: свой или чужой.
Подводя итоги, стоит отметить, что в рассмотренных работах за эталон клавиатурного почерка рассматривается величина удержания каждой клавиши с учетом возможной погрешности. В процессе аутентификации рассматривается некая идеализированная совокупность данных величин.
В текущей работе предполагается несколько иной подход анализа составляющих клавиатурного почерка, заключающийся в переходе от непосредственно длительностей между удержаниями клавиш к частотной составляющей.
Алгоритм динамической аутентификации
Для успешного функционирования работы системы аутентификации в первую очередь необходимо разработать систему идентификации, которая с большим процентом вероятности и с минимумом ошибок позволит определять оператора.
Принцип работы модели системы аутентификации, ответственной за сбор данных о пользователе, имеет следующий вид, представленный на Рисунке 1.

Рисунок 1. Принцип работы системы аутентификации
Признаками, позволяющими идентифицировать оператора, при вводе текста с клавиатуры являются:
– длительность ввода всего текста;
– временной промежуток между нажатиями на клавишу;
– длительность печати знаков препинания;
В ходе работы рассмотрен признак, характеризующий временной промежуток между нажатиями на клавиши. Данный выбор обусловлен тем, что, на основе вышеприведенных сведений о возможностях ввода текста, справедливо предположение, что длительность между нажатиями на клавиши у разных операторов будет разная. Остальные характеристики могут лишь являться дополнениями данного признака: длительность ввода всего текста может быть схожа у разных операторов и без иных характеристик не информативна. Аналогично и длительность печати знаков препинания: при усовершенствовании системы идентификации данные признаки позволят повысить эффективность системы.
Таким образом, на вход системы, в свою очередь поступает последовательность данных о длительности между парами клавиш.
Данные сведения представлены в виде матрицы A, имеющей размерность 33х75, таким образом, имеется 2475 результатов. Однако в данную матрицу не включены следующие элементы: знаки препинания и последовательное нажатие на пробел, точка и нажатие на пробел, запятая и нажатие на пробел, двоеточие и нажатие на пробел, точка с запятой и нажатие на пробел, пробел и тире, тире и пробел, пробел и открытая кавычка, закрытая кавычка и пробел, а также точка и точка, если осуществляется ввод многоточия. Таким образом, сумма элементов матрицы составляет 2484 элемента. Данный результат учитывает лишь ввод по правилам правописания. Тем не менее, при наборе существуют ситуации, когда осуществляется ввод не по правилам, при опечатке. Данные пары не будут учитываться в связи с тем, что опечатки, ввод не по правилам – события не частые, следовательно, смысловую нагрузку несут не высокую.
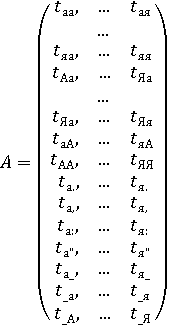 , ,
где tNM – длительность нажатия между клавишами N и M в мс,
нижнее подчеркивание – пробел.
Система, анализирующая среднюю длительность той или иной пары символов и соотносящая их с базой данных, будет не оптимизированной в плане ресурсопотребления, но, возможно, достойной для рассмотрения в перспективе, поэтому имеется необходимость в более оперативной системе. Для этого целесообразно перейти к математической статистике [7]. Необходимо определить, какие статистические данные будут полезны при выполнении операции аутентификации.
Предполагается следующий алгоритм: оператор вводит рассматриваемый текст, затем анализируется матрица типа А: из матрицы A извлекаются все имеющиеся длительности tNM, далее рассматривается матрица B. Если рассматриваемая длительность встречается единожды, то в матрицу B заносится число «1», если данная длительность встретилась несколько раз, то заносится число, соответствующее количеству ее совпадений. Таким образом, интерес в данном случае представляет не длительность между конкретными нажатиями на клавиши, а сколько раз встретилась длительность ti, то есть длительность не привязанная к конкретным клавишам, в отличие от tNM.
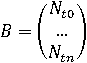 , ,
где N – количество совпадений длительности ti.
Справедливо будет предположить, что Nti – случайная величина, поскольку невозможно предположить, какое значение она примет, но известно конечное число 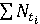 , равное количеству всех элементов матрицы А. , равное количеству всех элементов матрицы А.
Множество значений N = {N1,N2,...,Nn}, которые принимает данная рассматриваемая случайная величина – выборка значений случайной величины N, общее количество составляет n элементов.
Как показывает опыт статистических исследований, чем большее количество элементов имеет исследуемая выборка, тем более достоверные результаты имеет результат эксперимента. Таким образом, для повышения качества исследований, необходимо рассмотреть достаточное количество выборки элементов Ni. Данное количество возможно увеличить при использовании объемного текста при осуществлении ввода. Однако слишком объемный текст может утомить оператора, возможно появление опечаток, замедление ввода, соответственно, уменьшение достоверности статистических результатов. Таким образом, путем экспериментальных исследований необходимо определить ту необходимую и достаточную длину текста, которая позволит получить максимально возможный достоверный результат.
В целях дальнейшего анализа возникает необходимость группировки исследуемых элементов. Исследуемый статистический ряд рассматриваемых элементов представляет собой вариационный ряд:
N = {N1,N2,...,Nn},
где 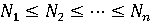 . .
Следующим шагом, после построения данного вариационного ряда, является группировка исследуемых элементов в определенные полуинтервалы одинаковой длины l, которые содержат элементы 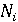 . Будет получено: . Будет получено:
[t1; t2), [t2; t3),..., [tn-1; tn).
Далее, необходимо перейти к, так называемому, интервальному вариационному ряду (Таблица 1):
Таблица 1. Интервальный вариационный ряд
|
[t1; t2)
|
[t2; t3)
|
...
|
[tn-1; tn)
|
|
p1
|
p2
|
...
|
pn
|
Где pi – частота, количество выборочных данных, которые попали в исследуемый полуинтервал [ti-1; ti).
Таким образом, над исследуемыми данными была проведена операция группировки выборочных данных. Для частот p1,p2,...,pn справедливы следующие свойства.
Свойство 1. Сумма всех частот pi равно количеству всех элементов матрицы А.
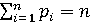 . .
Перед формулировкой свойства 2, необходимо ввести новое понятие, относительная частота Pi, которая представляет собой отношение частоты pi к общему количеству исследуемых интервалов n:
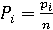 . .
Свойство 2. Сумма относительных частот Pi равна единице.
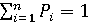 . .
Также интерес представляет и следующая величина – плотность относительных частот:
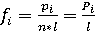 . .
Данная величина позволяет отобразить на гистограмме полученные значения вариационного ряда, что в свою очередь позволит получить представление о плотности распределения исследуемых характеристик.
Ниже предлагается метод построения данной гистограммы.
Ось абсцисс представляет собой множество точек (t1,t2,…,tn).
По оси ординат необходимо проложить отрезки [t1;t2],[t2;t3], соответствующие уровню Ni. Далее, от каждого отрезка прокладываются перпендикуляры к оси абсцисс, образуя прямоугольник. Таким образом, получена гистограмма распределения исследуемой величины, имеющая примерный вид, изображенный на Рисунке 2.
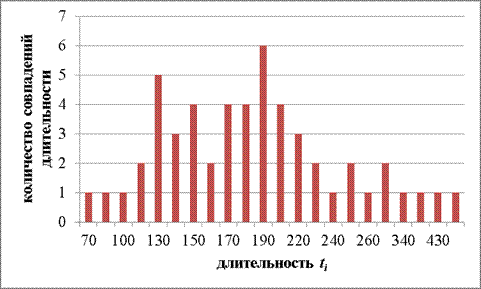
Рисунок 2. Гистограмма распределения исследуемой величины
Немаловажным для анализа является дискретный вариационный ряд и полигон выборочного распределения, который возможно построить, ориентируясь на предыдущие величины.
В данном случае необходимо рассмотреть дискретный вариационный ряд. Для этого необходимо ввести новый параметр сk, который является серединой отрезка [tk-1;tk] представляет собой следующую таблицу (Таблица 2).
Таблица 2. Дискретный вариационный ряд
Данный дискретный вариационный ряд имеет следующее свойство.
Свойство. Отрезки [ck-1;ck] имеют длину l.
Действительно, поскольку отрезки [tk-1;tk] имеют длину l, соответственно, длина отрезков [ck-1;ck] аналогично имеет длину l.
Таким образом, предстоит работа с выборкой значений исследуемой дискретной случайной величины Nti, имеющей следующий закон распределения.
Таблица 3. Распределение случайной величины Nti
Далее, целесообразно рассмотреть следующие характеристики.
Математическое ожидание случайной величины Nti, вычисляемой по формуле:
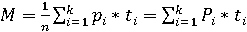 . .
Дисперсия случайной величины Nti вычисляется по формуле:
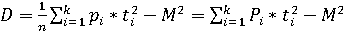 . .
Среднее квадратичное отклонение вычисляется по следующей формуле:
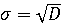 . .
Итак, имея в распоряжении три характеристики случайной величины ставится задача идентификации того или иного оператора, имея данные характеристики.
Экспериментальные результаты
Было принято решение проводить эксперименты в два этапа: первый этап – исследовать большую группу операторов и проанализировать, отличаются ли исследуемые величины (математическое ожидание и среднее квадратичное отклонение) одного оператора от другого. Второй этап – провести несколько повторных вводов одного и того же текста с целью проверить, насколько будут изменяться исследуемые величины у одного и того же оператора.
Первый этап исследований.
На данном этапе было исследовано пять операторов. В дальнейшем, данные операторы будут под обозначениями «оператор 1», «оператор 2», …, «оператор n». Экспериментальные исследования проводились на одной и той же персональной электронно-вычислительной машине, на одной и той же клавиатуре.
Было принято, длительность свыше 600 мс не рассматривать, поскольку значения данной области представляют собой вынужденные остановки оператора, которые не являются постоянными величинами и не несут в себе информативную составляющую.
На рисунках 3 – 7 представлены результаты ввода операторами одного и того же экспериментального текста.
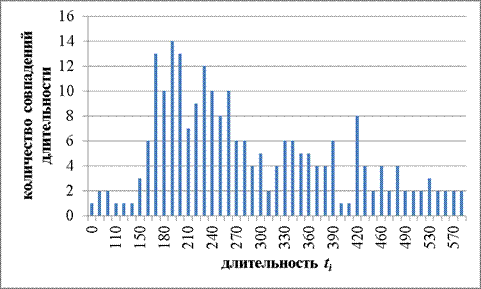
Рисунок 3. Результаты оператора 1
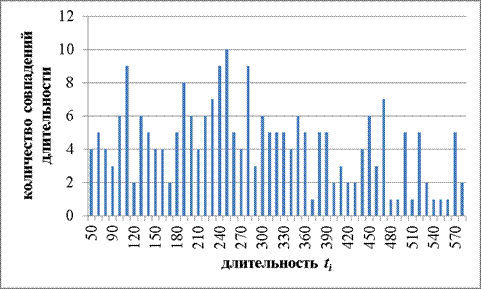
Рисунок 4. Результаты оператора 2
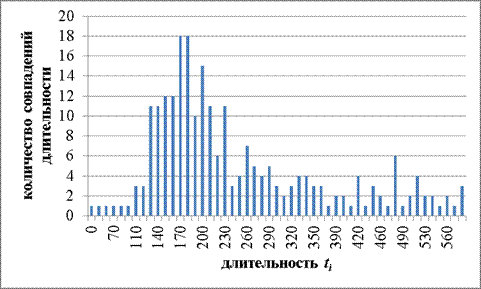
Рисунок 5. Результаты оператора 3
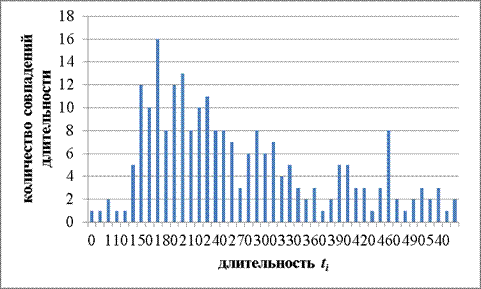
Рисунок 6. Результаты оператора 4
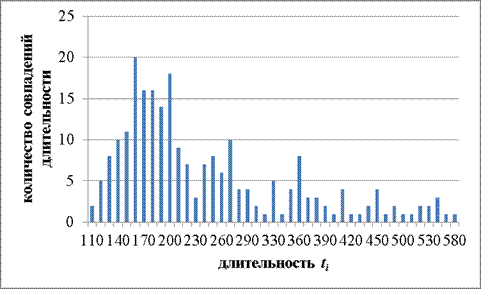
Рисунок 7. Результаты оператора 5
Ниже представлены результаты эксперимента: математическое ожидание длительности ti, дисперсия и среднее квадратичное отклонение для каждого из операторов (Таблица 4).
Таблица 4. Результаты исследований пяти операторов
|
Оператор
|
Оператор 1
|
Оператор 2
|
Оператор 3
|
Оператор 4
|
Оператор 5
|
|
Величина
|
|
Математическое ожидание
|
287.51
|
285.89
|
250.21
|
270.09
|
245.30
|
|
Дисперсия
|
13885.94
|
19318.58
|
15564.24
|
12525.43
|
11653.97
|
|
Среднее квадратичное отклонение
|
117.84
|
138.99
|
124.76
|
111.92
|
107.95
|
Анализируя данные величины, можно отметить, что отличия в значениях имеются, особенно учитывая тот факт, что операторы для исследования были отобраны среднестатистические. Под данной категорией подразумеваются лица, набирающие текст наполовину в слепую, не использующие десятипальцевый метод набора.
Таким образом, данными экспериментальными результатами вопрос о наличии определенных индивидуальных характеристиках в клавиатурном почерке закрыт: характеристики, несомненно, отличаются, однако вопрос о достаточности таких характеристик для гарантированной аутентификации остается открытым.
Следующая задача в рамках текущей работы: определить, насколько будут изменяться исследуемые величины у одного и того же оператора. В связи с этим были исследованы два оператора среднестатистического уровня набора текста.
Для первого исследуемого было предложено ввести текст 3 раза. Результаты представлены ниже.
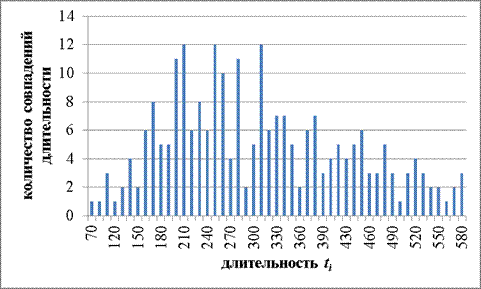
Рисунок 8. Первая попытка оператора 1’
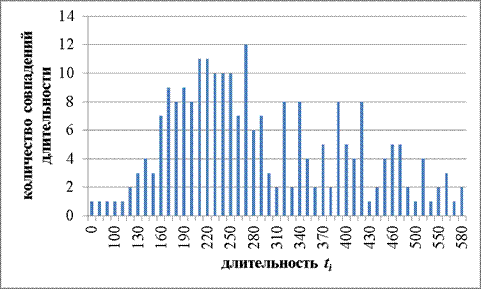
Рисунок 9. Вторая попытка оператора 1’
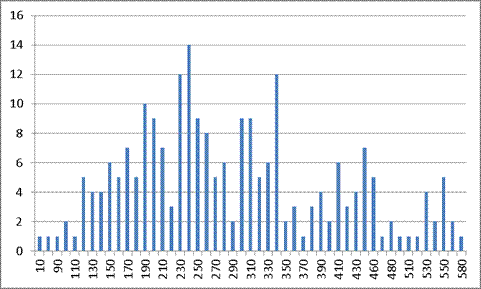
Рисунок 10. Третья попытка оператора 1’
Аналогично предыдущим исследованиям, ниже представлены результаты эксперимента (Таблица 5).
Таблица 5. Результаты исследований оператора 1’
|
Попытка
|
Попытка 1
|
Попытка 2
|
Попытка 3
|
|
Величина
|
|
Мат. ожидание
|
310.54
|
291.53
|
290.00
|
|
Дисперсия
|
14046.98
|
13292.59
|
14099.12
|
|
Среднее квадратичное отклонение
|
118,52
|
115,29
|
118,74
|
Данные результаты можно пояснить следующим образом: первая попытка представляет собой знакомство с текстом и его запоминание, при второй попытке текст уже частично запомнен и требуется уже меньшее количество времени для ориентирования в тексте. Третья попытка – установление четкой средней величины длительности между нажатиями на клавиши при наличии текста в памяти у оператора и его частичного привыкания к расположению клавиш на клавиатуре. Как показывает эксперимент, уже при второй попытке оператор показал стабильный результат при малом среднеквадратичном отклонении. Величина отклонения первой и третьей попытки равны, что свидетельствует о стандартной величине разброса длительностей между нажатиями на клавиши.
При следующем эксперименте будет предпринято две попытки ввода текста оператором, для отслеживания исследуемых величин.
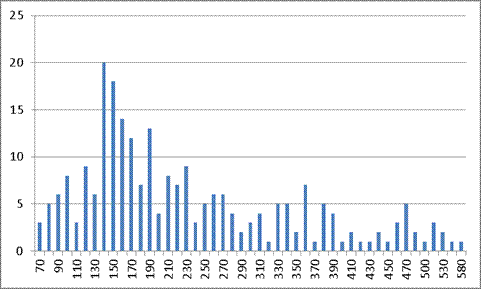
Рисунок 11. Первая попытка оператора 2’
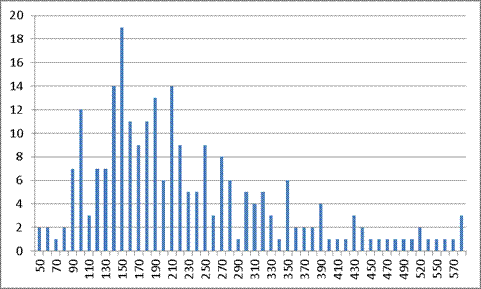
Рисунок 12. Вторая попытка оператора 2’
Таблица 6. Результаты исследований оператора 2’
|
Попытка
|
Попытка 1
|
Попытка 2
|
|
Величина
|
|
Мат. ожидание
|
231.45
|
227.78
|
|
Дисперсия
|
13549.34
|
13254.32
|
|
Среднее квадратичное отклонение
|
116.40
|
115.13
|
Результаты первого ввода имеют практически равномерное распределение по всей области, за исключением области примерно от 110 мс до 230 мс. Значение математического ожидания и среднеквадратичного отклонения подтверждают выводы первого эксперимента: при второй и следующих попытках данные величины незначительно уменьшаются.
Таким образом, исходя из данных результатов, можно сделать вывод: попытка идентифицировать того или иного оператора, исходя из величин математического ожидания и среднего квадратичного отклонения возможна.
Вывод
Таким образом, была исследована тематика клавиатурного почерка. Были рассмотрены и изучены публикации, связанные с данной областью. Результаты имеются и, как показывает практика, данная тематика привлекает все больше внимания специалистов в области информационных технологий за ее новизну, простоту использования для пользователя и за отсутствие дополнительных аппаратных компонентов для ее использования.
Также в рамках данной работы были рассмотрены статистические составляющие, предназначенные для успешной аутентификации. Далее были проведены экспериментальные исследования с участием семи операторов. Исследования были разделены на два этапа: первый этап заключался в подтверждении того, что каждый оператор имеет индивидуальные величины математического ожидания, дисперсии и среднего квадратичного отклонения. Результаты первого этапа подтвердили гипотезу: каждый из операторов продемонстрировал уникальные величины.
Второй этап исследований заключался в том, чтобы подтвердить гипотезу о том, что при следующих попытках ввода, данные величины останутся в этих же областях. Экспериментальные данные показали, что разброс значений составляет в первом эксперименте примерно 4 %, в случае со вторым оператором 1,6 %. Несомненно, необходимо организовать дальнейшие эксперименты с участием большего числа операторов и определить, сколько примерно будет составлять разброс значений у каждого из операторов. Также требуется определить дополнительные факторы распознавания клавиатурного почерка для повышения точности аутентификации. В целом, по результатам текущих исследований, можно отметить, что аутентификация посредством клавиатурного почерка имеет перспективы.
Дальнейшая цель исследований – сформировать базу данных клавиатурного почерка различных операторов и определить точность распознавания, используя текущие характеристики. Также определить дополнительные механизмы для более точной аутентификации.
Библиография
1. Руководящий документ. Защита от несанкционированного доступа к информации. Термины и определения [Электронный ресурс]: Руководящий документ. Защита от несанкционированного доступа к информации. Термины и определения – Режим доступа: http://www.consultant.ru/cons/cgi/online.cgi?req=doc&base=EXP&n=513377#08399505376741514 (13.05.2018).
2. Болл Р.М., Коннел Дж. Х., Панканти Ш., Ратха Н.К., Сеньор Э.У. Руководство по биометрии. Москва: Техносфера. 2007. 368 с.
3. Баранов С.О., Абрамов Д.Б. Технология биометрической аутентификации пользователя по венозному рисунку кистей рук // Вестник СибАДИ. 2017. №2. С. 134-139.
4. Лапина Т.И., Лапин Д.В., Петрик Е.А. Биометрическая аутентификация пользователя по рукописному почерку // Известия юго-западного государственного университета. Серия: управление, вычислительная техника, информатика. Медицинское приборостроение. 2013. №2. С. 7-12.
5. Савинов А.Н. Методы, модели и алгоритмы распознавания клавиатурного почерка в ключевых системах: автореферат диссертации на соискание ученой степени кандидата технических наук: 05.13.19. -Санкт-Петербург, 2013. - 19 с.
6. Брюхомицкий Юрий Анатольевич Гистограммный метод распознавания клавиатурного почерка // Известия ЮФУ. Технические науки. 2010. №11. С. 55-62.
7. Самаров К.Л. Математика. Учебно-методическое пособие по разделу Математическая статистика. Москва: Резольвента. 2009. 30 с.
References
1. Rukovodyashchii dokument. Zashchita ot nesanktsionirovannogo dostupa k informatsii. Terminy i opredeleniya [Elektronnyi resurs]: Rukovodyashchii dokument. Zashchita ot nesanktsionirovannogo dostupa k informatsii. Terminy i opredeleniya – Rezhim dostupa: http://www.consultant.ru/cons/cgi/online.cgi?req=doc&base=EXP&n=513377#08399505376741514 (13.05.2018).
2. Boll R.M., Konnel Dzh. Kh., Pankanti Sh., Ratkha N.K., Sen'or E.U. Rukovodstvo po biometrii. Moskva: Tekhnosfera. 2007. 368 s.
3. Baranov S.O., Abramov D.B. Tekhnologiya biometricheskoi autentifikatsii pol'zovatelya po venoznomu risunku kistei ruk // Vestnik SibADI. 2017. №2. S. 134-139.
4. Lapina T.I., Lapin D.V., Petrik E.A. Biometricheskaya autentifikatsiya pol'zovatelya po rukopisnomu pocherku // Izvestiya yugo-zapadnogo gosudarstvennogo universiteta. Seriya: upravlenie, vychislitel'naya tekhnika, informatika. Meditsinskoe priborostroenie. 2013. №2. S. 7-12.
5. Savinov A.N. Metody, modeli i algoritmy raspoznavaniya klaviaturnogo pocherka v klyuchevykh sistemakh: avtoreferat dissertatsii na soiskanie uchenoi stepeni kandidata tekhnicheskikh nauk: 05.13.19. -Sankt-Peterburg, 2013. - 19 s.
6. Bryukhomitskii Yurii Anatol'evich Gistogrammnyi metod raspoznavaniya klaviaturnogo pocherka // Izvestiya YuFU. Tekhnicheskie nauki. 2010. №11. S. 55-62.
7. Samarov K.L. Matematika. Uchebno-metodicheskoe posobie po razdelu Matematicheskaya statistika. Moskva: Rezol'venta. 2009. 30 s.
|
 Рус
Рус









