|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Мартышенко Н.С., Мартышенко С.Н.
Алгоритмизация процесса анализа достоверности данных анкетных онлайн-опросов
// Программные системы и вычислительные методы.
2018. № 4.
С. 76-85.
DOI: 10.7256/2454-0714.2018.4.28367 URL: https://nbpublish.com/library_read_article.php?id=28367
Алгоритмизация процесса анализа достоверности данных анкетных онлайн-опросов
Мартышенко Наталья Степановна
кандидат экономических наук
профессор, Владивостокский государственный университет экономики и сервиса
690014, Россия, Приморский край, г. Владивосток, ул. Гоголя, 41
Martyshenko Natal'ya Stepanovna
PhD in Economics
Professor, the department of International Marketing and Trade, Vladivostok State University of Economics and Service
690014, Russia, Primorsky Krai, Vladivostok, Gogolya Street 41

|
natalya.martyshenko@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
Мартышенко Сергей Николаевич
кандидат технических наук
профессор, кафедра Математики и моделирования, Владивостокский государственный университет экономики и сервиса
690014, Россия, Приморский край, г. Владивосток, пр. Красного Знамени, 96, кв. 17
Martyshenko Sergei Nikolaevich
PhD in Technical Science
Professor, Department of Mathematics and Modeling, Vladivostok State University of Economics and Service
690014, Russia, Primorskii krai, g. Vladivostok, pr. Krasnogo Znameni, 96, kv. 17
|
|
sergey.martishenko@vvsu.ru
|
|
 |
|
DOI: 10.7256/2454-0714.2018.4.28367
Дата направления статьи в редакцию:
13-12-2018
Дата публикации:
10-01-2019
Аннотация:
С распространением онлайн-сервисов конструирования форм для проведения онлайн-опросов существенно возросло количество исследователей, использующих анкетные опросы в практике научных исследований. Одной из проблем, которая присутствовала при традиционной форме опроса на бумажном носителе и перешла в онлайн-опросы, является проблема достоверности данных. Большинство исследователей, применяющих онлайн-опросы, имеют более высокие запросы к автоматизации исследований. Они не готовы предпринимать значительные усилия для повышения достоверности данных. В настоящей работе предлагается к рассмотрению алгоритм, позволяющий автоматизировать процесс анализа достоверности данных анкетных опросов. Предложенный алгоритм основан на использовании процедуры скользящего экзамена для тестирования отдельных многомерных наблюдений, полученных в ходе онлайн-опроса. Основная гипотеза, заложенная в основу разработанного метода, состоит в том, что подчиненность вопросов анкеты некоторой общей тематике приводит к возникновению некоторых латентных связей между ответами, которые нарушаются при случайных ответах. Для тестирования анкетных данных разработан многомерный статистический критерий. Метод очень прост в использовании и доступен даже для не искушенных исследователей.
Ключевые слова:
анкетный опрос, качество данных, онлайн-опрос, многомерные статистические методы, латентные связи, критерий качества данных, скользящий экзамен, компьютерная технология, интернет-сервис, номинальные признаки
Abstract: With the proliferation of online forms design services for online surveys, the number of researchers using questionnaires in research practice has increased significantly. One of the problems that was present in the traditional form of the survey on paper and was transferred to online surveys is the problem of data reliability. Most researchers using online surveys have higher queries to automate research. They are not ready to make significant efforts to increase the reliability of the data. In this paper, we propose to consider an algorithm for automating the process of analyzing the reliability of questionnaire data. The proposed algorithm is based on the use of a sliding exam procedure for testing individual multidimensional observations obtained during an online survey. The main hypothesis underlying the developed method consists in the fact that the subordination of the questionnaire questions to some general topic leads to some latent connections between answers that are violated by random answers. A multi-dimensional statistical criterion was developed for testing personal data. The method is very simple to use and is available even for not sophisticated researchers.
Keywords: questionnaire, data quality, online survey, multivariate statistical methods, latent connections, criterion fquality of data, sliding exam, computer technology, Internet service, nominal features
Введение
В настоящее время в исследовании социально-экономических процессов все большее распространение получают анкетные опросы [1]. В большой степени это связано с распространением онлайн-опросов, реализуемых с помощью различных специализированных программных сервисов, позволяющих не только конструировать онлайн-опросы, но и осуществлять типовую обработку данных [2-5]. Среди распространенных онлайн-сервисов можно выделить такие сервисы: Google Forms, Survey Monkey, Survio, Typeform Simpoll и другие. Новые методы производства данных требуют разработки более совершенных методов их обработки. Одной из проблем, которая присутствовала при традиционной форме опроса на бумажном носителе и перешла и в онлайн-опросы, является проблема достоверности данных. При онлайн-опросах эта проблема даже усугубилась [6, 7]. Во-первых, сбор данных осуществляется без прямого контакта с интервьюером и чаще всего является более обезличенным. Во-вторых, возросли объемы собираемых данных. В-третьих, онлайн-опрос привел не только к сокращению времени на сам опрос, но и времени, отводимого на полный цикл обработки данных. В-четвертых, большинство исследователей, применяющих онлайн-опросы, имеют более высокие запросы к автоматизации исследований. Они не готовы предпринимать значительные усилия для повышения достоверности данных. Проблема качества данных, полученных с помощью онлайн-опросов, поднимается во многих научных публикациях. В качестве примера зарубежных публикаций можно привести работы [8-12]. Среди работ российских ученых можно выделить следующие публикации [13-17]. Авторами был разработан ряд методов автоматизации обработки анкетных данных, которые прошли апробацию при анализе данных анкетных опросов, проводимых как в онлайн, так и офлайн режимах [18, 19]. В настоящей работе предлагается к рассмотрению алгоритм, позволяющий автоматизировать процесс анализа достоверности данных анкетных опросов. Преимущество алгоритма состоит в том, что он позволяет анализировать всю (или почти всю) совокупность данных, представленных в анкетах.
Предмет исследования
Предметом исследований являются данные, полученные в ходе онлайн анкетных опросов.
Такие данные формируют многомерные выборки признаков таблиц статистических данных, которые используются для анализа социально-экономических процессов и явлений. В большинстве анкетных форм, представленных в интернет, в качестве основного типа вопросов используют вопросы с набором альтернативных вариантов ответов. Такие анкеты требуют минимального времени заполнения и наиболее понятны большинству респондентов. Ответы на такие вопросы можно представить в виде таблицы объект - свойство. Строки таблицы представляют собой наблюдения (анкеты), а столбцы ассоциированы с отдельными вопросами (признаки). В таком же виде можно представить вопросы, требующие ответов по шкале Лайкерта. Вопросы, требующие заполнения таблицы типа «сетка флажки», имеют аналогичную форму представления. Каждому такому вопросу соответствует несколько столбцов таблицы данных по количеству строк таблицы типа «сетка флажки». Все перечисленные виды измерения можно причислить к измерениям в номинальной шкале.
Все большее распространение в анкетных опросах начинают находить открытые вопросы, которые имеют некоторые преимущество перед вопросами с заданным набором альтернатив. После обработки таких данных они тоже могут быть приведены к номинальной шкале. Обработка открытых вопросов основана на применении операции типизации [8, 9]. Числовые данные тоже можно свести к ограниченному списку значений путем ранжирования по заданным границам интервалов значений.
Для формализованного описания алгоритма введем некоторые обозначения. Пусть произведена выборка объемом n (количество анкет-строк в таблице данных). Обозначим совокупность номинальных признаков в таблице данных как
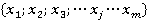 , ,
где m – количество номинальных признаков, 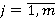 . .
Элементы множества можно воспринимать как случайные переменные или идентификаторы номинальных признаков. Будем считать, что каждый столбец данных представлен ограниченным набором (множеством) значений признака 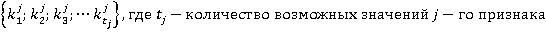 . Для упрощения записи заменим конкретные значения признака их номерами в списке значений признака. Тогда множество значений признака j можно представить множеством . Для упрощения записи заменим конкретные значения признака их номерами в списке значений признака. Тогда множество значений признака j можно представить множеством 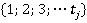 . .
Основные принципы работы алгоритма
Работа алгоритма основывается на вполне реалистичных предположениях (гипотезах) относительно выборки, сформированной по данным анкетного опроса.
Первая гипотеза состоит в предположении, что основная масса анкетных данных отвечает требованию достоверности. То есть, большинство респондентов понимали суть заданных вопросов и ответственно относились к ответам на вопросы анкеты.
Вторая гипотеза состоит в том, что вопросы анкеты объединены некоторой общей тематикой, что неизбежно приводит к возникновению некоторых латентных связей между ответами. То есть, данным присущи некоторые статистические закономерности, обусловленные внутренней логикой анкеты. Ответы на одни вопросы анкеты влияют в статистическом смысле на другие ответы. Следуя логике, ответы на отдельные вопросы могут быть либо несовместимы, либо маловероятны. Например, если респондент в одном вопросе указывает что он вегетарианец, а в другом среди наиболее часто заказываемых им блюд в столовой указывает только мясные блюда, то такие ответы противоречат друг другу. Или если респондент отмечает, что он вполне здоров и далее замечает, что тратит большие деньги на лекарства на лечение, - это выглядит нелогично. Нелогичные ответы респондента могут быть вызваны и непреднамеренным действием, например, при недопонимании вопроса анкеты. Однако, такие ответы все равно нельзя признать достоверными.
На основе данных гипотез можно попытаться выделить такие анкеты, которые плохо согласуются с общими закономерностями, присущими выборке.
Работа алгоритма организована по принципу скользящего экзамена. Каждое наблюдение тестируется с помощью определенного критерия. Критерий построен на оценке разницы между отдельным наблюдением и совокупностью наблюдений оставшейся выборкой. После расчета критерия для одного наблюдения оно возвращается в выборку, а из нее изымается следующее наблюдение для тестирования. Критерий учитывает латентные связи между всеми парами признаков.
Упорядочив значение критерия можно выделить «подозрительные» наблюдения (анкеты), которые выпадают из общего ряда наблюдений. Выделенные «подозрительные» анкеты не отбрасываются автоматически, а подвергаются дополнительному содержательному анализу по оценке правдоподобия ответов на вопросы анкеты с целью выяснения причин выделения таких анкет в ряду прочих. И только после установления того, что такие анкеты нельзя признать достоверными, такие анкеты отбрасываются.
Пример расчета критерия оценки достоверности данных анкетного опроса
Алгоритм расчета критерия рассмотрим на примере модельных данных. Объем модельной выборки составляет 101 наблюдение (n=101). Выборка представлена пятью номинальными признаками 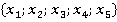 . Для простоты предположим, что количество возможных значений всех признаков одинаково. В примере принято . Для простоты предположим, что количество возможных значений всех признаков одинаково. В примере принято 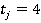 . Считается, что предварительно выборка номинальных значений признаков была преобразована путем замены возможных значений признаков их номерами в списке. То есть, . Считается, что предварительно выборка номинальных значений признаков была преобразована путем замены возможных значений признаков их номерами в списке. То есть, 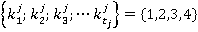 для всех признаков. для всех признаков.
Для наглядности расчеты, полностью совпадающие, многомерные наблюдения выборки (анкеты) были сгруппированы. Для каждой уникальной последовательности значений признаков была рассчитана «частота встречаемости в выборке» Qs, (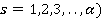 , где , где 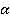 – количество уникальных анкет, встречавшихся в выборке – количество уникальных анкет, встречавшихся в выборке 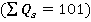 . В нашем примере . В нашем примере 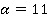 Сгруппированная выборка представлена в компактном виде в таблице 1. Сгруппированная выборка представлена в компактном виде в таблице 1.
Таблица 1. Сгруппированная выборка модельных данных
|
Номер уникальной
последовательности
ответов
|
Значения признаков выборки
|
Частота встречаемости в выборке Qs
|
Значение критерия
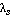
|
|
x1
|
x2
|
x3
|
x4
|
x5
|
|
1
|
1
|
1
|
4
|
3
|
1
|
21
|
0,790
|
|
2
|
1
|
1
|
4
|
3
|
2
|
19
|
0,902
|
|
3
|
1
|
1
|
3
|
3
|
2
|
18
|
0,792
|
|
4
|
2
|
2
|
3
|
2
|
3
|
10
|
0,182
|
|
5
|
3
|
3
|
2
|
3
|
2
|
10
|
0,256
|
|
6
|
1
|
2
|
1
|
3
|
2
|
8
|
0,424
|
|
7
|
2
|
1
|
3
|
4
|
2
|
7
|
0,272
|
|
8
|
3
|
4
|
3
|
4
|
3
|
3
|
0,094
|
|
9
|
2
|
2
|
3
|
3
|
2
|
2
|
0,356
|
|
10
|
4
|
1
|
3
|
1
|
4
|
2
|
0,090
|
|
11
|
1
|
2
|
2
|
2
|
3
|
1
|
0,076
|
Для каждого наблюдения выборки рассчитывается значение критерия 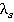 . Алгоритм расчета критерия рассмотрим на примере наблюдения . Алгоритм расчета критерия рассмотрим на примере наблюдения  , которое стоит последним в таблице уникальных значений (строка номер 11). Для примера, было выбрано наблюдение, которое наиболее контрастирует со всеми остальными. Для определенности выделенное наблюдение будем называть контрольным. Для обозначения такого наблюдения будем использовать аббревиатуру КН (контрольное наблюдение). Всю оставшуюся выборку, за исключением контрольного наблюдения, назовем обучающей выборкой (ОВ). , которое стоит последним в таблице уникальных значений (строка номер 11). Для примера, было выбрано наблюдение, которое наиболее контрастирует со всеми остальными. Для определенности выделенное наблюдение будем называть контрольным. Для обозначения такого наблюдения будем использовать аббревиатуру КН (контрольное наблюдение). Всю оставшуюся выборку, за исключением контрольного наблюдения, назовем обучающей выборкой (ОВ).
По данным полной многомерной выборки рассчитываются частотные ряды по каждому признаку. Графики частотных рядов представлены на рис. 1. Для одномерных рядов реальных выборок, как и в примере, характерно наличие некоторого значения с наибольшей частотой.
На практике частота сочетания значений пар признаков тоже подчиняется некоторой статистической зависимости. В рассматриваемом критерии учитывается связь между всеми парами признаков.
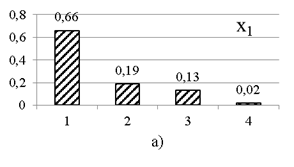 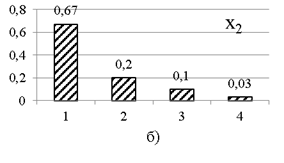
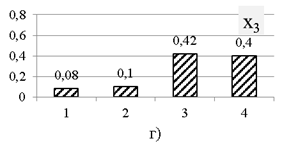 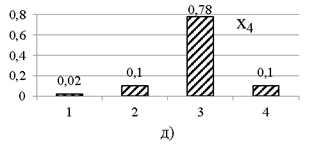
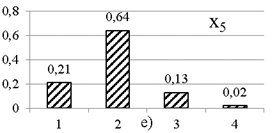
Рис. 1. Частотные ряды по пяти признакам выборки модельных данных
Рассмотрим множество возможных сочетаний пар признаков выборки из 5-ти признаков. Сочетания возможных пар признаков выборки может быть представлено полным графом G с количеством ребер равным d, рассчитываемым по формуле(1). Для 5-ти признаков d=10.
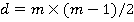 (1) (1)
Расчет элементов критерия для контрольного наблюдения 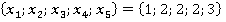 представлен в таблице 2. Второй столбец таблицы содержит все возможные пары признаков. Такие же сочетания пар будут и для любого другого наблюдения выборки. представлен в таблице 2. Второй столбец таблицы содержит все возможные пары признаков. Такие же сочетания пар будут и для любого другого наблюдения выборки.
В третьем столбце таблицы 2 указаны конкретные значения признаков для рассматриваемого контрольного наблюдения. Далее рассчитывается количество таких пар в обучающей выборке без учета кратности (четвертый столбец). Например, пара 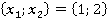 встречалась только однажды в уникальном наблюдении под номером 6 в таблице 1: встречалась только однажды в уникальном наблюдении под номером 6 в таблице 1: 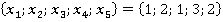 . Такая пара может встречаться и в других уникальных наблюдениях (максимум во всех, что крайне маловероятно). . Такая пара может встречаться и в других уникальных наблюдениях (максимум во всех, что крайне маловероятно).
Таблица 2. Расчет критерия для наблюдения 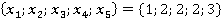
|
Пара
|
Значения
признаков
в КН
|
Количество
пар в ОВ
без учета кратности
|
Кратность по ОВ
|
Количество пар в ОВ
с учетом кратности
|
Частота
пары
в ОВ
|
Вес
пары
|
Вклад пары
|
|
1
|
2
|
…
|
10
|
|
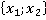
|
{1;2}
|
1
|
8
|
|
|
|
8
|
0,08
|
0,2
|
0,016
|
|
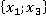
|
{1;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
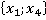
|
{1;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
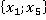
|
{1;3}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
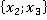
|
{2;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
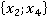
|
{2;2}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
|
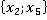
|
{2;3}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
|
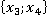
|
{2;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
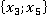
|
{2;3}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
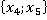
|
{2;3}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
Для пар обучающей выборки, где встречается рассматриваемая пара значений контрольного наблюдения отводятся несколько столбцов таблицы, объединенных под общим названием «Кратность ОВ». Следующий столбец содержит сумму встречаемости пары во всей обучающей выборке. Частота пары рассчитывается путем нормирования встречаемости по объему обучающей выборки (в нашем случае n=100).
Для рассматриваемого контрольного наблюдения обнаружено только по одному совпадению пар в четырех случаях (четыре единицы в столбце «Количество пар в ОВ без учета кратности» в таблице 2). Каждое уникальное значение имеет свою кратность Qs. Например, наблюдение под номером 6 в ОВ имеет кратность 8, а другое наблюдение 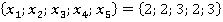 под номером 4, имеющее аналогичную пару под номером 4, имеющее аналогичную пару 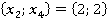 в контрольной выборке имеет кратность 10. Суммарная кратность повторения совпадений каждой пары значений обучающей выборки и контрольного наблюдения записана в столбце «Количество пар в ОВ с учетом кратности» таблицы 2. в контрольной выборке имеет кратность 10. Суммарная кратность повторения совпадений каждой пары значений обучающей выборки и контрольного наблюдения записана в столбце «Количество пар в ОВ с учетом кратности» таблицы 2.
Далее рассчитывается частота встречаемости каждой пары обучающей выборки в контрольном наблюдении (столбец «Частота» в таблице 2). Для этого «Количество пар в ОВ с учетом кратности» делится на объем обучающей выборки (в нашем случае 100).
Однако в общем случае все пары неравнозначны. Количество возможных вариантов ответов зависит от количества значений признаков, составляющих пару (в нашем случае для всех признаков 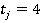 ). Количество возможных вариантов значений каждой пары признаков ). Количество возможных вариантов значений каждой пары признаков 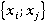 равно равно 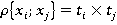 (в нашем случае все для всех пар признаков (в нашем случае все для всех пар признаков 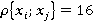 ). Поэтому для различных пар необходимо ввести поправочный коэффициент (вес пары). Веса для разных сочетаний пар признаков в общем случае рассчитываются по формуле (2): ). Поэтому для различных пар необходимо ввести поправочный коэффициент (вес пары). Веса для разных сочетаний пар признаков в общем случае рассчитываются по формуле (2):
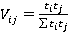 (2) (2)
В нашем примере все пары будут иметь один и тот же вес 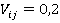 . Затем рассчитывается «вклад каждой пары» как произведение частоты пары на вес. Суммирование по вкладам каждой пары дает общее значение критерия . Затем рассчитывается «вклад каждой пары» как произведение частоты пары на вес. Суммирование по вкладам каждой пары дает общее значение критерия 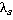 . В данном случае для контрольного наблюдения значение критерия равно . В данном случае для контрольного наблюдения значение критерия равно 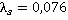 . На рис. 2 представлен график упорядоченных значений критерия для всех уникальных наблюдений выборки. . На рис. 2 представлен график упорядоченных значений критерия для всех уникальных наблюдений выборки.
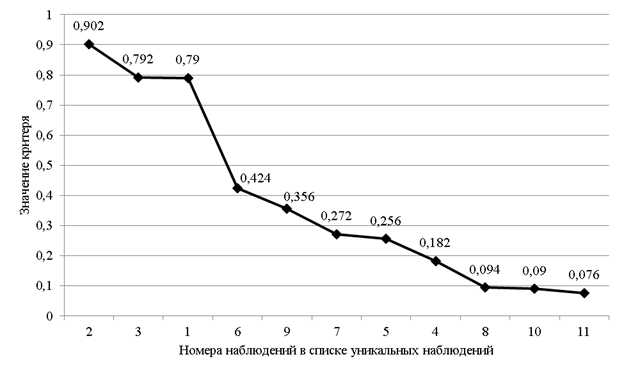
Рис. 2. График значений критерия для уникальных наблюдений из таблицы 1
На горизонтальной оси указаны номера уникальных наблюдений. Из графика видно, что три наблюдения выбиваются из общего ряда наблюдений выборки, поэтому их можно рассматривать как «сомнительные», с точки зрения достоверности данных. В реальной ситуации такие наблюдения необходимо подвергнуть содержательному анализу ответов респондентов для выяснения причин, в результате которых алгоритмом были выделены именно эти наблюдения. Поскольку «подозрительных» анкет, как правило, не так много, то такой анализ обычно не вызывает особых затруднений. Блок-схема алгоритма представлена на рис.3.
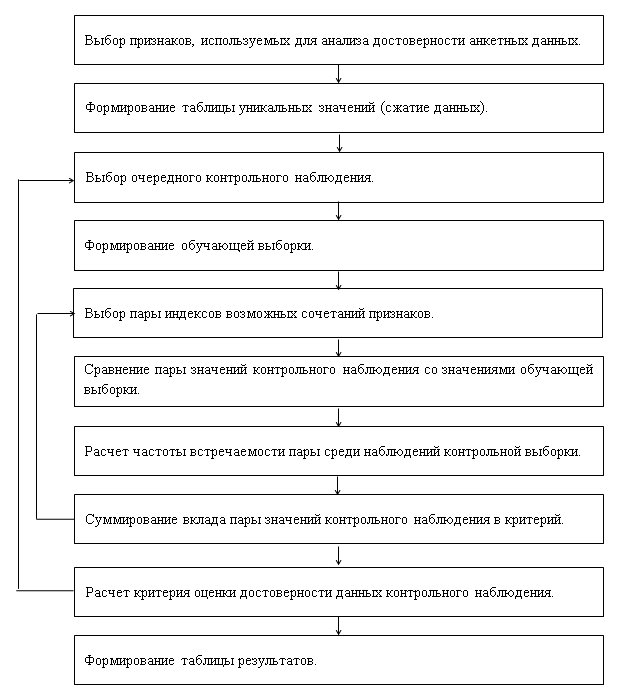
Рис. 3. Блок-схема алгоритма оценки достоверности наблюдений анкетных данных
На основе предложенного метода анализа достоверности анкетных данных была разработана компьютерная программа в среде EXCEL. Кроме модельных данных, программа была протестирована и на реальных данных и показала хорошие результаты.
Заключение
Основным достоинством предложенного метода является то, что он позволяет оперативно анализировать многомерные выборки таблиц данных, сформированных на основе онлайн-опросов. Метод очень прост в использовании и доступен даже для не искушенных исследователей.
Преимущество метода состоит в том, что позволяет учесть латентные связи, присущие исследуемому объекту. При недобросовестном отношении к опросу части респондентов они не задумываются о возможных статистических связях и тем самым порождают данные, выпадающие из общего ряда наблюдений. Если бы такие респонденты попытались предпринять попытку умышленной фальсификации ответов, то на заполнение такой анкеты потребовалось бы затратить времени больше, чем на предоставление объективной информации.
Для анализа достоверности данных онлайн-опросов целесообразно использовать ряд критериев. Например, можно использовать критерии, которые были разработаны автором ранее для различных типов данных [20].
Возможно, предложенный метод в дальнейшем может быть использован для классификации наблюдений. Например, в графике на рис. 3 можно выделить три зоны, которые могут быть положены в основу классификации. Эта возможность может быть определена в результате дальнейших исследований.
Библиография
1. Долгоруков А.М. Интернет и будущее социологии // Мониторинг общественного мнения: экономические и социальные перемены. – 2015. – № 2 (125). – С. 32-43.
2. Беликова Ю.В. Сравнительный анализ сервисов для проведения онлайн опросов // Актуальные научные исследования в современном мире. – 2016. – № 5–4 (13). – С. 36–41.
3. Ефимова Д.М., Ермолаев С.В. Сравнительный анализ сервисов для продвижения опроса в сети интернет // Вестник Российского экономического университета им. Г.В. Плеханова. Вступление. Путь в науку. – 2014. – № 1-2 (9). – С. 88-95.
4. Насретдинова М.М. Актуальность онлайн исследований в России // Психология, социология и педагогика. – 2014. – № 6 (33). – С. 24.
5. Некрасов С.И. Сравнение результатов онлайн-и оффлайн-опросов (на примере анкет разной сложности) // Социология: методология, методы, математическое моделирование. – 2011. – № 32. – С. 53-74.
6. Фарахутдинов Ш.Ф. Профессиональные респонденты камень предкновения онлайн-опросов в современной России // Телескоп: журнал социологических и маркетинговых исследований. – 2011. – № 2. – С. 45-47.
7. Шкурин Д.В. Сравнительная оценка качества данных офлайн и онлайн-опросов // Дискуссия. – 2015. – №
8. – С. 101–105. 8. Alessi E. J., Martin J. I. Conducting an internet-based survey: Benefits, pitfalls, and lessons learned // Social Work Research. – 2010. – Vol. 34. – N 2. – P. 122–128.
9. Hunter L. Challenging the reported disadvantages of e-questionnaires and addressing methodological issues of online data collection // Nurse researcher. – 2012. – Vol. 20. – N 1. – P. 11–20.
10. McPeake J., Bateson M., O’Neill A. Electronic surveys: how to maximise success // Nurse researcher. – 2014. – Vol. 21. – N 3. – P. 24–26.
11. Phillips K. Data Use: An evaluation of quality-control questions // Quirk’s Marketing Research Review. December. 2013. [Электронный ресурс]. Режим доступа: http://www.quirks.com/articles/2013/20131205.aspx (дата обращения 17 декабря 2018).
12. Zaveri A. et al. Quality assessment for linked data: A survey // Semantic Web. – 2016. – Vol. 7. – №. 1. – P. 63-93.
13. Галицкий Е.Б., Мальцева П.В. Потенциальные источники ошибок в данных онлайн-опросов // Практический маркетинг. – 2013. – № 10 (200). – С. 2-8.
14. Мавлетова А.М., Малошонок Н.Г., Терентьев Е.А. Влияние элементов приглашения на увеличение доли откликов в онлайн-опросах // Социология: методология, методы, математическое моделирование. – 2014. – № 38. – С. 72-95.
15. Малошонок Н.Г., Терентьев Е.А. Влияние дизайна на качество данных в онлайн-опросах студентов // Мониторинг общественного мнения: экономические и социальные перемены. – 2014. – № 6 (124). – С. 15-27.
16. Моисеев С.П., Савинкова Ю.К. Выборка, направляемая респондентом, в онлайн-опросе: к вопросу о динамике и качестве // Мониторинг общественного мнения: экономические и социальные перемены. – 2014. – № 6 (124). – С. 43-50.
17. Федоровский А.М. Качество онлайн-опросов. Методы проверок // Мониторинг общественного мнения: экономические и социальные перемены. – 2015. – № 3 (127). – С. 28-35.
18. Мартышенко С.Н. Методическое обеспечение анализа данных мониторинга социально-экономических процессов в муниципальных образованиях // Экономика и менеджмент систем управления. – 2012. – Т. 6. – № 4-2. – С. 259-267.
19. Мартышенко С.Н., Мартышенко Н.С. Методы обработки нечисловых данных в социально-экономических исследованиях // Вестник Тихоокеанского государственного экономического университета. – 2006. – № 4 (40). – С. 48-57.
20. Мартышенко С.Н., Мартышенко Н.С. Современные методы обработки маркетинговой информации : монография. – Владивосток: Издательство ВГУЭС, 2014. – 148 с.
References
1. Dolgorukov A.M. Internet i budushchee sotsiologii // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2015. – № 2 (125). – S. 32-43.
2. Belikova Yu.V. Sravnitel'nyi analiz servisov dlya provedeniya onlain oprosov // Aktual'nye nauchnye issledovaniya v sovremennom mire. – 2016. – № 5–4 (13). – S. 36–41.
3. Efimova D.M., Ermolaev S.V. Sravnitel'nyi analiz servisov dlya prodvizheniya oprosa v seti internet // Vestnik Rossiiskogo ekonomicheskogo universiteta im. G.V. Plekhanova. Vstuplenie. Put' v nauku. – 2014. – № 1-2 (9). – S. 88-95.
4. Nasretdinova M.M. Aktual'nost' onlain issledovanii v Rossii // Psikhologiya, sotsiologiya i pedagogika. – 2014. – № 6 (33). – S. 24.
5. Nekrasov S.I. Sravnenie rezul'tatov onlain-i offlain-oprosov (na primere anket raznoi slozhnosti) // Sotsiologiya: metodologiya, metody, matematicheskoe modelirovanie. – 2011. – № 32. – S. 53-74.
6. Farakhutdinov Sh.F. Professional'nye respondenty kamen' predknoveniya onlain-oprosov v sovremennoi Rossii // Teleskop: zhurnal sotsiologicheskikh i marketingovykh issledovanii. – 2011. – № 2. – S. 45-47.
7. Shkurin D.V. Sravnitel'naya otsenka kachestva dannykh oflain i onlain-oprosov // Diskussiya. – 2015. – №
8. – S. 101–105. 8. Alessi E. J., Martin J. I. Conducting an internet-based survey: Benefits, pitfalls, and lessons learned // Social Work Research. – 2010. – Vol. 34. – N 2. – P. 122–128.
9. Hunter L. Challenging the reported disadvantages of e-questionnaires and addressing methodological issues of online data collection // Nurse researcher. – 2012. – Vol. 20. – N 1. – P. 11–20.
10. McPeake J., Bateson M., O’Neill A. Electronic surveys: how to maximise success // Nurse researcher. – 2014. – Vol. 21. – N 3. – P. 24–26.
11. Phillips K. Data Use: An evaluation of quality-control questions // Quirk’s Marketing Research Review. December. 2013. [Elektronnyi resurs]. Rezhim dostupa: http://www.quirks.com/articles/2013/20131205.aspx (data obrashcheniya 17 dekabrya 2018).
12. Zaveri A. et al. Quality assessment for linked data: A survey // Semantic Web. – 2016. – Vol. 7. – №. 1. – P. 63-93.
13. Galitskii E.B., Mal'tseva P.V. Potentsial'nye istochniki oshibok v dannykh onlain-oprosov // Prakticheskii marketing. – 2013. – № 10 (200). – S. 2-8.
14. Mavletova A.M., Maloshonok N.G., Terent'ev E.A. Vliyanie elementov priglasheniya na uvelichenie doli otklikov v onlain-oprosakh // Sotsiologiya: metodologiya, metody, matematicheskoe modelirovanie. – 2014. – № 38. – S. 72-95.
15. Maloshonok N.G., Terent'ev E.A. Vliyanie dizaina na kachestvo dannykh v onlain-oprosakh studentov // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2014. – № 6 (124). – S. 15-27.
16. Moiseev S.P., Savinkova Yu.K. Vyborka, napravlyaemaya respondentom, v onlain-oprose: k voprosu o dinamike i kachestve // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2014. – № 6 (124). – S. 43-50.
17. Fedorovskii A.M. Kachestvo onlain-oprosov. Metody proverok // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2015. – № 3 (127). – S. 28-35.
18. Martyshenko S.N. Metodicheskoe obespechenie analiza dannykh monitoringa sotsial'no-ekonomicheskikh protsessov v munitsipal'nykh obrazovaniyakh // Ekonomika i menedzhment sistem upravleniya. – 2012. – T. 6. – № 4-2. – S. 259-267.
19. Martyshenko S.N., Martyshenko N.S. Metody obrabotki nechislovykh dannykh v sotsial'no-ekonomicheskikh issledovaniyakh // Vestnik Tikhookeanskogo gosudarstvennogo ekonomicheskogo universiteta. – 2006. – № 4 (40). – S. 48-57.
20. Martyshenko S.N., Martyshenko N.S. Sovremennye metody obrabotki marketingovoi informatsii : monografiya. – Vladivostok: Izdatel'stvo VGUES, 2014. – 148 s.
|
 Рус
Рус










