|
DOI: 10.7256/2585-7797.2018.1.25686
Дата направления статьи в редакцию:
11-03-2018
Дата публикации:
21-04-2018
Аннотация:
Данная статья посвящена проблемам транскрибирования рукописных материалов переписи населения Норвегии 1950 г. Они представляют собой 801 000 двусторонних опросных листов, каждый из которых был отсканирован. Программы оптического распознавания печатного текста совершенствуются на протяжении более чем четырех десятилетий. В настоящее время исследователи стремятся применить аналогичные методы для транскрибирования рукописного материала. В статье проанаизирован опыт работы Центра исторической документации Норвегии Университета Тромсо по распознаванию рукописного текста, рассматриваются проблемы использования различных методов распознавания текста и возможности их применения к номинативным источникам. Из-за трудностей с распознаванием и выделением самостоятельных рукописных символов, изображения целых слов математически группируются по соответствию подобным изображениям или же идет поиск этих слов-изображений в ранее транскрибированных источниках. После контроля качества распознавания программное обеспечение использует номера строк для размещения информации из транскрибируемых ячеек, после чего они становятся частью базы данных переписи. Кроме того, разрабатывается специальное программное обеспечение для обработки рукописных числовых кодов, данных о профессиях, образовании и т. д. Предложенные в статье методы дают возможность подняться на новый уровень и качество транскрибирования рукописного текста и могут быть применены для распознавания записей номинативных источников РОссии, в частности метрических книг и записей ЗАГС. Основными задачами по-прежнему остаются поиск методов и алгоритмов, которые оптимально подбирают связи между различными переменными и рационализация методов интерактивной корректуры.
Ключевые слова:
базы данных, Перепись населения Норвегии, связывание записей, транскрибирование, Оптическое распознавание текста, глубокое обучение машин, нейронные сети, Исторический регистр населения, графического интерфейса, рукописный текст
Abstract: The article addresses the issue of transcribing handwritten materials of the 1950 Norwegian Population Census. These are 801 000 scanned double sided questionnaires. Optical character recognition programs have been improving for over four decades. Now researchers aim to extend similar techniques to handle handwritten historical source material. The article analyzes studies carried by the Center of Historical Documents at the University of Tromsø which address handwritten text recognition as well as considers the use of various text recognition techniques as far as nominative sources are concerned. Since it is difficult to distinguish and separate individual handwritten characters, the words are mathematically clustered according to image similarity or searched for within sources that have been transcribed earlier. After the recognition quality control, the software uses the line numbers to place the information taken from the transcribed cells. After that the latter become a part of the census database. Moreover, special software has been developed to process handwritten numerical codes, data on occupations and education, etc. The methods offered in the article provide for handwritten texts transcribing quality improvement and can be used to recognize nominative source notes in Russia, for instance, parish registers and vital records. The main goals are still the search for methods and algorithms which optimally link different variables as well as the rationalization of interactive proofread methods.
Keywords: databases, Norwegian population census, record linkage, transcription, OCR, Deep learning, neural network, Historical Population Register, graphical user interface, hand writing
Транскрибирование исторических данных, проводимое в Норвежском центрe исторической документации Университета Тромсо, с самого начала было тесно связано с компьютерными методами оптического считывания информации c бумажных носителей. При этом, первоначально информация вводилась не через централизованные компьютерные терминалы крупных исследовательских центров, а силами машинисток, набиравших текст исторических документов на обычных печатных машинках. Университетский сканер Kurzweil OCR, приобретенный в 1978 году, мог считывать только шрифт пишущих машинок — OCR-B.
С начала 1980-х годов мы стали использовать компьютеры для оптического распознавания машинописных текстов. Имевшееся в нашем распоряжении программное обеспечение, увы, давало возможность распознать только шрифты и тексты определенного типа. Использование компьютера в работе со списками норвежских фермеров, составленных в 1886 г. в форме сложных таблиц, стало возможно благодаря программному обеспечению, специально разработанному российскими IT-специалистами. Метод был описан в одном из выпусков журнала «History and Computing»[1].
Современное программное обеспечение распознает печатный текст классическим латинским шрифтом, однако оно по-прежнему не справляется с готическими шрифтами и текстами на национальных языках, алфавиты которых содержат специфические символы. Проблемой является также отсутствие стандартных пробелов между словами, мелкие графы, разделительные вертикальные линии и т.д., которые не дают возможности машине корректно распознать информацию.
В то время как техника оптического распознавания печатных символов динамично развивается, распознавание рукописного текста все еще малонадежно и требует разработки особого программного обеспечения. Где-то посередине между этими полюсами находится вариант распознавания записей в опросных листах, которые использовались в США: вручную, но печатными буквами, где каждая буква вписывалась в отдельную клетку [2]. Аналогичный прием применялся при заполнении индивидуальных регистрационных листов во время проведения переписей населения в 1891 и 1920 гг. в Норвегии в, а также во Франции и Германии. При сканировании такого рода источников ключевые слова идентифицируются с высокой степенью достоверности, кроме того, автоматически распознаются некоторые цифры и коды. Что касается имен, профессий и другой персональной информации, то ее невозможно считать с помощью OCR и подобных ей техник, из-за сложностей распознавания и разделения на отдельные буквы слов рукописного текста. Вместо этого целые слова математически группируются в кластеры в зависимости от степени схожести. Таким образом, информация ряда полей, например, с указанием места рождения, может быть расшифрована целиком, без разбивки на отдельные буквы, если вид слова будет хоть немного соответствовать кластерным образцам написания этого слова. Поскольку расположение полей с идентичной информацией в формах переписей стандартно, это позволяет рационализировать транскрибирование формуляра клетка за клеткой — слово за словом. В частности, такой метод был применен при транскрибировании записей браков, заключенных в Барселоне в 1451–1905 гг. [3]. Аналогичный подход используется в швейцарском проекте интерактивного транскрибирования текстов Transkribus (https://transkribus.eu/Transkribus/). Располагая обширным массивом отсканированных и транскрибированных материалов переписей, мы можем использовать этот метод для обучения машин с искусственным интеллектом, что значительно расширит возможности в развитии оптического распознавания рукописных текстов.
Перепись населения 1950 г.[1]
Перепись 1891 г. уже выложена в интернете, а перепись 1920 г. станет доступна через два года, в 2020 г., в соответствии с законом об охране персональных данных. И тогда Национальный архив сможет отправить материалы переписи за границу для транскрибирования, большую часть расходов на которое оплатят коммерческие компании, предоставляющие услуги генеалогам. Переписи 1801, 1865, 1875, 1891, 1900 и 1910 гг. уже расшифрованы таким способом и находятся в открытом доступе. В то же время, большой интерес представляют и более поздние переписи, и прежде всего 1930 и 1910 гг., содержащие материалы, которых могут быть использованы, в частности, в медицинских исследованиях. Они были отсканированы Национальным архивом в рамках нашего проекта по созданию «Исторического Реестра Населения Норвегии» (Historical Population Register for Norway). Данные всех последующих переписей Норвегии, начиная с 1960 г., вошли в ресурс «Центральный Реестр населения Норвегии» (Central Population Register), который охватывает период с 1964 г. до настоящего времени. Кроме того, в нашем распоряжении имеется «Реестр причин смерти» (Causes of Death Register), данные которого, начиная с 1951 г., также занесены в электронную базу данных. После транскрибирования материалов переписи 1950 г., содержащей информацию о 3,3 миллионов людей, ее можно будет связать с Реестром причин смерти и изучить обстоятельства и экологическую обстановку взросления значительных групп населения Норвегии. Однако осуществить транскрибирование переписи 1950 г. без использования коммерческих ресурсов генеалогических структур довольно сложно. Тоже касается переписей 1930 и 1946 гг., а также закрытых пока для исследователей записей о рождениях за 1935–1964 гг. и переписи 1946 г. В период второй мировой войны в Норвегии, как и во многих других странах, переписей не проводилось [4].
Материалы переписи 1950 года представляют собой 801 тысячу опросных листов — формуляров размером 29.7x70.7 см, заполненных вручную с обеих сторон. Они были отсканированы, в результате чего были получены более чем 1,6 миллиона изображений в форматах jpeg и jpeg2000 — в сжатом и полном разрешении соответственно. В каждом формуляре могло быть зарегистрировано до 10 человек, и в дополнение к обычным переменным переписи в них содержится информация об образовании, религиозной принадлежности и предыдущих передвижениях. Кроме того, в формуляре предусмотрены специальные строки для внесения информации в закодированной форме, в том числе о профессии и других персональных характеристиках. Обратная сторона формуляра содержит адресную информацию, как правило, название фермы и налоговый номер в сельской местности или название улицы и номера дома в городах. Соблюдение строгой последовательности изображений формуляра имеет решающее значение для дальнейшей работы.
Все изображения были проанализированы с помощью программы Analyseform, разработанной Норвежским вычислительным центром (Norwegian Computing Center) и примененной Норвежским Центром исторических данных (Norwegian Historical Data Centre)[2]. Эта программа идентифицирует тип формуляра и разделяет его поля на отдельные изображения, которые хранятся в базе данных. В ней каждое изображение связано с номером формуляра, номером конкретной строки и клетки. При этом, информация, оказавшаяся за границей клетки, отведенной для нее, может быть утрачена. Программа рассчитана на разделение фамилии, первого и второго имени зарегистрированного человека по отдельным изображениям. Однако это не удается в тех случаях, когда между фамилией и именем нет пробела, пробел находится посередине имени или два имени написаны одно над другим. Программа также рассчитана на распознавание цифровых кодов, но плохо справляется с двух и трехзначными числами, и решения как ее обучить отделять одну цифру от другой пока не найдено.
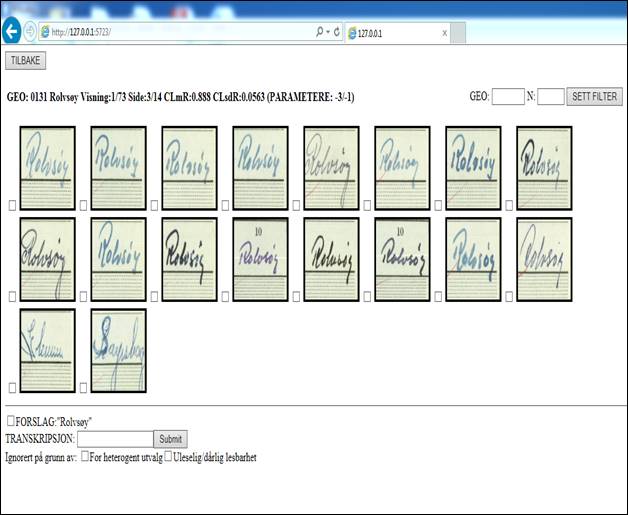
Каждая клетка с текстом анализируется с помощью 30 математических переменных, которые характеризуют текстовое изображение. На основе этой информации клетки группируются в кластеры и далее анализируются с помощью интерактивного графического интерфейса (GUI), разработанного Kåre Bævre из Национального института здравоохранения Норвегии (National Institute of Health). В процессе анализа на экран компьютера выводятся возможные варианты мест рождений (как правило, названия муниципалитетов), которые похожи на изображения анализируемого кластера, а также вариант возможного транскрибирования (cм. рис. 1). После этого оператор должен исключить ошибочно сгруппированные изображения и нажать «ОК» или изменить вариант транскрибирования остальных. Это достаточно эффективный метод ручного управления транскрибированием миллионов изображений, содержащих информацию о месте рождения, поскольку число вариантов таких названий в сельской местности Норвегии ограничено. Добровольцы, привлеченные к транскрибированию источников этим методом, считают, что этот процесс также увлекателен, как и разгадывание Судоку, но в отличие от Судоку, транскрибирование имеет еще и большое практическое значение.
Рис. 1. Графический интерфейс для редактирования изображений с рукописным текстом мест рождения
К сожалению, информация о дате рождения заносилась в очень мелкие клетки формы переписи, и места для того чтобы вписать день, месяц и год рождения было недостаточно. Поскольку автоматически транскрибировать эту информацию оказалось невозможно, пришлось сделать это вручную, оплатив услуги индийской компании Suntech. Передача в Индию изображений, содержащих информацию о дате рождения, не являлась нарушением закона о защите персональных данных, поскольку они никак не могли быть связаны с конкретными персонами. Спустя четыре месяца Suntech вернули таблицы с отформатированными датами рождения в шестизначном или восьмизначном формате. Выборочные проверки показали, что точность их транскрибирования находится в пределах допустимой погрешности — 3%, и обнаруженные несоответствия часто связаны с проблемой некорректного занесения этой информации в источнике (cм. рис. 2).
Рис. 2. Пример проблемной записи даты рождения в источнике

Мы можем сгруппировать и изображения с информацией об именах по такому же принципу, по 30 характеристикам, и применить графический интерфейc GUI для их транскрипции, так же, как и в случае с местами рождений. Однако идентичные имена, встречаются в источнике гораздо реже, чем названия муниципалитетов. Еще реже встречаются идентичные комбинации, состоящие из имени и фамилии. Поэтому, прежде чем использовать GUI необходимо прогнать изображения с именами через программу Analyseform, для выделения самостоятельных элементов сложных имен. Но и она, в ее настоящем варианте, не срабатывает почти в 20 процентах случаев. В результате, даже после разделения имен на отдельные части их транскрипция с применением интерактивного интерфейса GUI является более трудоемкой и время затратной, чем транскрипция такого же количества документов с местами рождений. Поэтому нам пришлось разработать альтернативный вариант транскрипции личных имен, используя метод установления связей между записями (record linkage).
Установление связей между записями
У нас есть доступ к номинативной информации Центрального реестра населения Норвегии 1964 г., переписи 1960 г. и Реестра причин смерти, начиная с 1951 г. Вместе эти источники содержат имена, даты рождения и т. д. практически для всего населения Норвегии в 1950 г., поскольку эмиграция в то время была очень незначительной. Разумеется, отдельные лица не могут быть точно идентифицированы на основе имен и дат рождения, транскрибированных в Индии, исключение составляют редкие случаи, когда в семье рождались близнецы. А вот пары или группы лиц, проживавших вместе, идентифицировать возможно. На первом этапе мы выявили все семьи, зарегистрированные в переписи 1950 г., где имелось хотя бы два человека, чьи дни рождения совпадали с днями рождений двух людей в семьях из переписи населения 1960 года или Реестра населения 1964 г. Используя эти соответствия в именах и датах (исключая случаи с двойными именами), мы получили первый предположительный вариант прочтения изображений имен в переписи 1950 г. Всего таких оказалось 394 000 изображений, имена в которых были проверены на соответствие с помощью все того же графического интерфейса GUI. 353 000 из этих изображений содержали одно из 555 различных имен, некоторые из этих имен повторялись до сотни раз. Таким образом, прием объединенного анализа написанных от руки и напечатанных имен ускоряет процесс кластерного транскрибирования имен (cм. pис. 3).
Рис. 3. Графический интерфейс для редактирования изображений с рукописным и печатным текстом из разновременных источников
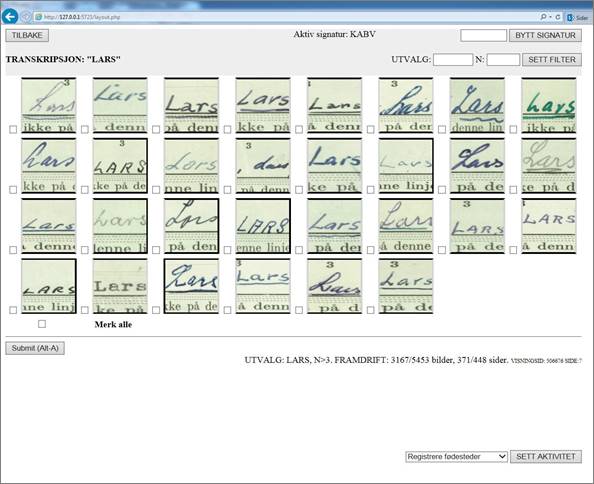
Следуя инструкции, операторы объединяют в один кластер имена, написание которых несколько отличается, например, «Niels» и «Nils», или «Olav» и «Olaf»; поскольку такие графемы часто смешиваются в реальной практике. С другой стороны, они не должны объединять такие имена, как «Maria» и «Marie», похожие в написании, но совершенно различные. Кроме того, из процесса кластерного анализа исключаются изображения, в которых оказываются соединены элементы разных имен. Все подобные случаи будут транскрибированы после обработки обновленной версией программы разделения имен, работа над улучшением которой активно ведется с помощью методов машинного обучения.
Прорыв в деле распознавания изображений произошел в связи с использованием инструментария нейросетевых технологий глубокого обучения машин нового поколения [5]. 353 000 распознанных машиной изображений использовались для обучения искусственной нейронной сети (ИНС), классифицирующей имена. Затем эту обученную ИНС применили для классификации оставшихся 3,4 миллионов не идентифицированных имен в переписи. Сеть предложила 10 наиболее вероятных имен, каждое с определенным числом баллов соответствия. Они снова были проверены уже вручную на основе того же графического интерфейса GUI, что и прежде. Задача была упрощена за счет идентификации в первую очередь лиц с уникальным днем рождения и именем, зарегистрированных в определенном месте, на предмет того подходит ли одно из 10 имен, предложенных искусственным интеллектом. С учетом некоторых дополнительных критериев были идентифицированы имена в еще 450 000 изображений. Этими и другими подобными методами можно значительно сократить процесс транскрипции 3,4 миллиона личных имен людей, зарегистрированных в переписи. Аналогичные методы могут быть использованы в распознавании вторых имен и даже фамилий, хотя, учитывая то, что вариантов фамилий значительно больше, чем личных имен, усилий на их транскрибирование потребуется больше. Искусственный интеллект может обучаться, используя изображения, в которых уже удалось идентифицировать имена, связав их с датами рождений, как описано выше. Чем больше искусственная нейронная сеть обучается, тем лучше работает ее интеллект, что, в итоге, сокращает необходимость проведения транскрибирования или проверки результатов вручную.
Обученные нейронные сети могут использоваться для обработки текста и кодов из других клеток формуляра переписи, со сведениями о поле, семейном положении и месте проживания. Для этого необходимо создать обучающую программу, обучить искусственную нейронную сеть, использовать ее для классификации изображений и, наконец, вручную проверить проведенную ею классификацию. При этом все числа в переписи сначала разделяются на отдельные цифры, затем искусственный интеллект проводит идентификацию каждой цифры, используя существующие довольно эффективные методы распознавания цифр, записанных вручную. Этот метод особенно продуктивен, когда известно точное количество цифр, содержащихся в каждой клетке формуляра, поскольку большая часть ошибок появляется из-за неверного разделения чисел на отдельные цифры. Для других клеток формуляра, например, с информацией об основном занятии, труднее использовать метод обучения машин с искусственным интеллектом, поскольку для каждого варианта занятия недостаточно тестовых данных.
Перепись 1950 г. будет включена в Исторический реестр населения Норвегии (Historical Population Register for Norway), для чего необходимо сохранить и расширить уже установленные связи с Центральным реестром населения 1964 г., переписями 1960 и 1910 г. и Реестром причин смерти 1951–1964 г. В процессе применения, описанного выше метода транскрибирования личных имен как раз устанавливаются связи между данными различных реестров. В процессе работы усилия направлены на установление как можно большего числа связей между записями на основании данных о дате рождения, имени и, если таковые имеются, месте рождения/проживания. Пока переписи 1920 и 1930 г. остаются недоступны из-за закона об охране персональных данных, можно связать данные более ранней переписи 1910 г. Это первая норвежская перепись, регистрационные листы которой включали не возраст, а дату рождения для всего населения страны. В 1891 и 1900 г. даты рождения отмечались только для детей младше двух лет.
Дополнительные характеристики для установления связей между записями
В дальнейшей привязке записей можно использовать фамилии и вторые имена, группируя их в кластеры и сравнивая с именами в более поздних переписях, аналогично методу работы с личным именем. Особую сложность представляет идентификация фамилий 255 000 женщин, которые вышли замуж в период между переписями 1950–1960 г. и взяли фамилию мужа. Законодательство того времени редко допускало иные поводы для изменения имен, но те, у кого были двойные имена могли начать использовать второе имя в качестве основного[3]. К сожалению, поле «предыдущее имя» редко заполняется в Центральном реестре населения, и у примерно половины населения информация о родителях в данном источнике также не указана.
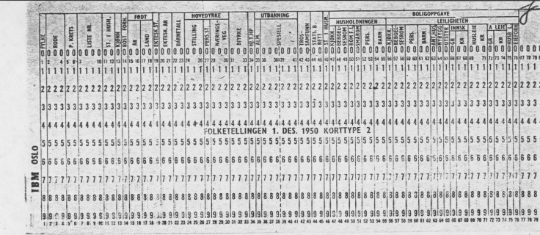
Перечисленные выше переменные являются основными, в процессе установления связей между записями переписи 1950 г. как с более ранними, так и более поздними номинативными источниками. Кроме того, информация о половой принадлежности автоматически считывается из источника и потом сравнивается на соответствие с именем в переписи. Естественно, если добавить дополнительные переменные: семейное положение, отношение к главе семьи, профессия, образование и миграция, то перепись 1950 г. будет еще более ценным источником для длительных по хронологии и кросс-секционных исследований. Использование метода кластеризации при работе с этими текстовыми полями потребует значительных ресурсов для проверки и редактирования кластеров, и кодирования информации на следующем этапе. Для этого мы используем числовые коды, которые Статистическое управление Норвегии проставляло в специальных строках формуляров переписи 1950 г. После этого коды были пробиты на перфокартах (см. рис. 4) и все результаты рассчитаны с помощью электромеханического оборудования. К сожалению, эти перфокарты не сохранились, их уничтожили чтобы освободить место для материалов переписи 1960 г., которая прошла до того, как Статистическое управление Норвегии перешло на использование нового поколения носителей для компактного хранения информации.
Рис. 4. Перфокарта, использованная для агрегации переписи 1950 г. в Норвегии
Распознавание кодов дополнительных переменных производится с помощью методов машинного обучения и библиотечных программ. ИТ-специалисты признали это возможным, так как в процессе кодирования материалов переписи 1950 г. принимало участие всего несколько сотрудников статуправления Норвегии. Коды проставляли красным карандашом, поэтому они хорошо различимы, а количество возможных альтернатив ограничено во всех полях, кроме «основного занятия». Для выделения и классификации трехзначных кодов, использованных в переписи, планируется использовать библиотеку глубокого обучения Tensorflow. Библиотеки этого класса дают возможность использовать современные технологии обработки изображений на мощных графических процессорах уровня GPU.
Планируется использовать два подхода. Первый подход включает обучение программы с использованием сета данных, состоящего из трехзначного числа-кода и аннотаций из сета рукописных чисел mnist (http://yann.lecun.com/exdb/mnist/). Аналогичный подход был использован для распознавания 5-значных чисел (https://github.com/thomalm/svhn-multi-digit), при этом точность результатов, полученных для однозначных чисел (99,7%) снизилась до 96,5% (https: // github.com/thomalm/svhn-multi-digit/blob/master/04-mnist-synthetic-model.ipynb). Для повышения точности результата в настоящее время создается дополнительный обучающий сет, основанный на репрезентативной выборке чисел из форм переписи. Второй подход предусматривает анализ отдельных цифр. К сожалению, этот метод работы с закодированной информацией не удастся применить при транскрибировании материалов переписи 1930 г., поскольку коды были прописаны на отдельных листах, которые не сохранились. Что касается переписи 1950 года, то ее материалы, по всем основным характеристикам в целом удается расшифровывать с помощью методов полуавтоматического транскрибирования. Основными задачами по-прежнему остаются поиск методов и алгоритмов, которые оптимально подбирают связи между различными переменными и рационализация методов интерактивной корректуры. Мы готовы к сотрудничеству со всеми, кто занимается транскрибированием и использованием данных номинативных источников [6], поскольку описанные здесь методы будут также полезны для транскрибирования метрических книг, записей ЗАГСов и других документов учета населения.
[1] Публикации, основанные на материалах переписи 1950 г., в том числе на английском языке, доступны по адресу: http://ssb.no/a/folketellinger/. Просто надо нажать на 1950 год. Книга с кодами имеется только на норвежском языке; инструкции для переписчиков на английском доступны по адресу http://rhd.uit.no/census/ft1950E.html
[2] В работе по поиску методов транскрибирования принимали участие также Kåre Bævre из Норвежского национального института здоровья; Lars Holden из Норвежского вычислительного центра и Lars Ailo Ballo, из Университета Тромсё.
[3] В качестве «middle» — среднего имени может выступать второе имя, данное при рождении, имя отца или даже фамилия, которых, кстати, тоже может быть две.
Библиография
1. Kliatskine V. et al. A structured method for the recognition of complex historical tables // History and Computing. 1997. Vol. 9 (1–3). P. 58–77.
2. Madhvanath S. et al. Reading handwritten US census forms // Proceedings of the Third International Conference on Document Analysis and Recognition. Vol. 1. IEEE Computer Society, 1995. P. 82–85.
3. Thorvaldsen G. et al. A Tale of Two Transcriptions. Machine-Assisted Transcription of Historical Sources // Historical Life Course Studies. 2015. Vol. 2 (1). P. 1–19.
4. Торвальдсен Г. Т. Номинативные источники в контексте всемирной истории переписей: Россия и Запад // Известия Уральского федерального университета. Серия 2. Гуманитарные науки. 2016. Т. 18. № 3 (154). С. 9–28.
5. Krizhevsky A., Sutskever I., Hinton G. E. Imagenet classification with deep convolutional neural networks // Advances in neural information processing systems 25. NIPS, 2012.
6. Главацкая Е. М., Торвальдсен Г. Т. Этно-религиозная и демографическая динамика в горной Евразии в конце XIX – начале XX вв.: проект создания Регистра населения Урала // Информационный бюллетень ассоциации «История и компьютер». 2016. № 45 (спецвыпуск). С. 251–254.
References
1. Kliatskine V. et al. A structured method for the recognition of complex historical tables // History and Computing. 1997. Vol. 9 (1–3). P. 58–77.
2. Madhvanath S. et al. Reading handwritten US census forms // Proceedings of the Third International Conference on Document Analysis and Recognition. Vol. 1. IEEE Computer Society, 1995. P. 82–85.
3. Thorvaldsen G. et al. A Tale of Two Transcriptions. Machine-Assisted Transcription of Historical Sources // Historical Life Course Studies. 2015. Vol. 2 (1). P. 1–19.
4. Torval'dsen G. T. Nominativnye istochniki v kontekste vsemirnoi istorii perepisei: Rossiya i Zapad // Izvestiya Ural'skogo federal'nogo universiteta. Seriya 2. Gumanitarnye nauki. 2016. T. 18. № 3 (154). S. 9–28.
5. Krizhevsky A., Sutskever I., Hinton G. E. Imagenet classification with deep convolutional neural networks // Advances in neural information processing systems 25. NIPS, 2012.
6. Glavatskaya E. M., Torval'dsen G. T. Etno-religioznaya i demograficheskaya dinamika v gornoi Evrazii v kontse XIX – nachale XX vv.: proekt sozdaniya Registra naseleniya Urala // Informatsionnyi byulleten' assotsiatsii «Istoriya i komp'yuter». 2016. № 45 (spetsvypusk). S. 251–254.
|
 Рус
Рус











